LDRANK / ENsEN: Query-biased Ranking of LOD Entities for Semantic Snippets
Web of Data / Web of Documents: ranking on the edge of two webs
The advances of the Linked Open Data (LOD) initiative are giving rise to a more structured Web of data. Indeed, a few datasets act as hubs (e.g., DBpedia) connecting many other datasets. They also made possible new Web services for entity detection inside plain text (e.g., DBpedia Spotlight), thus allowing for new applications that can benefit from a combination of the Web of documents and the Web of data.
Challenges and Contributions
To ease the emergence of these new applications, we propose a query-biased algorithm (LDRANK) for the ranking of web of data entities with associated textual data (e.g., the entities detected inside a Web page returned by a classical search engine as an answer to a user query). Our algorithm combines link analysis with dimensionality reduction. LDRANK is well adapted to sparse graphs for which textual data can be associated with the nodes. Indeed, LDRANK uses both the explicit structure of the graph and the implicit relationships that can be inferred from the text of the nodes.
We use crowdsourcing for building a publicly available and reusable dataset for the evaluation of query-biased ranking of Web of data entities detected in Web pages.
We show that, on this dataset, LDRANK outperforms the state of the art. Finally, we use this algorithm for the construction of semantic snippets of which we evaluate the usefulness with a crowdsourcing-based approach.
Contributors
 Pierre-Edouard Portier
Pierre-Edouard Portier  Mazen Alsarem
Mazen Alsarem  Sylvie Calabretto
Sylvie Calabretto  Harald Kosch
Harald Kosch
Software and demonstration
ENsEN (Enhanced Search Engine)
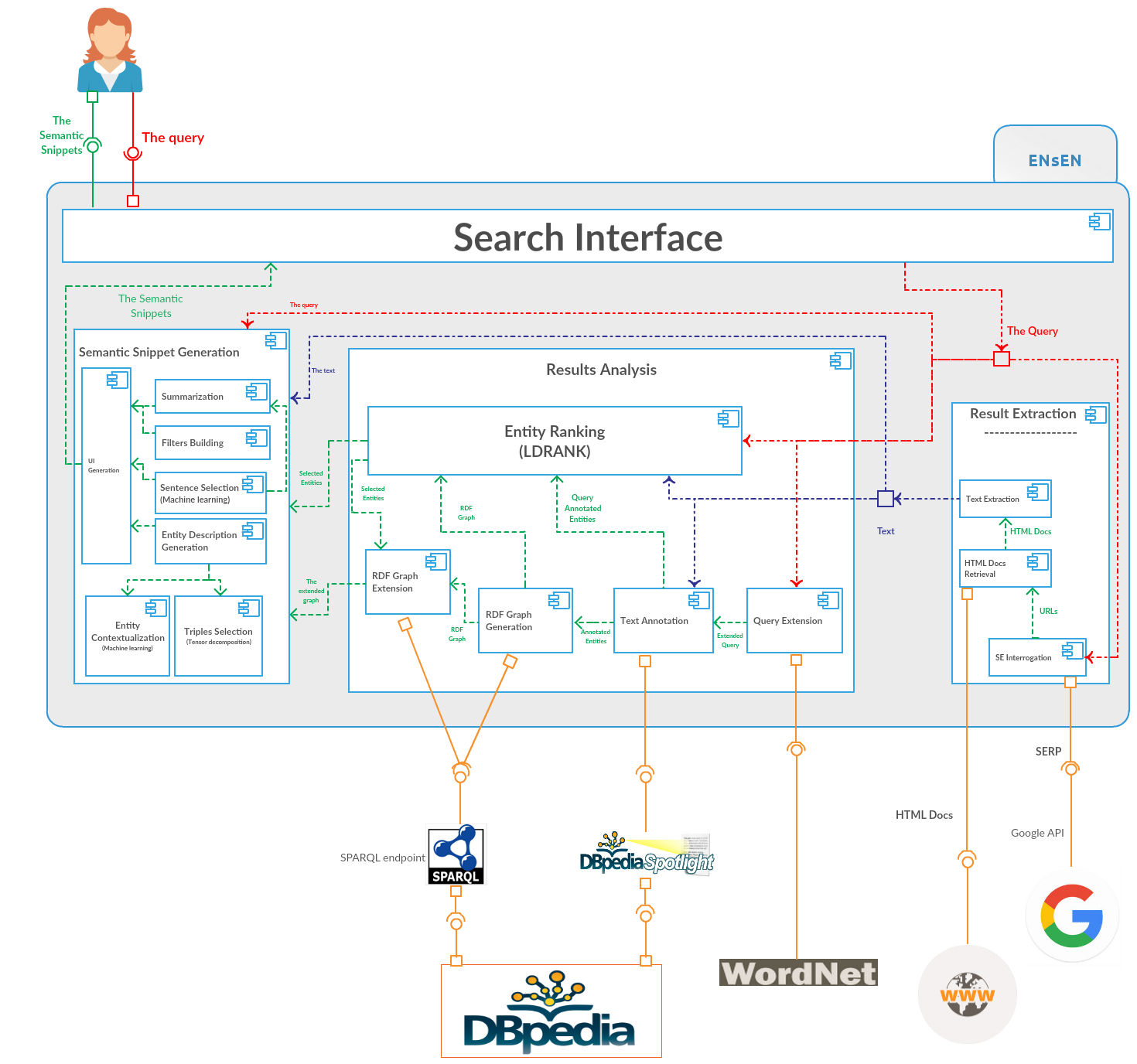
We used LDRANK at the core of ENsEN (Enhanced Search Engine):
a software system that enhances a SERP with semantic snippets.
Given the query, we obtain the SERP (we used Google for our experiments).
For each result of the SERP, we use DBpedia Spotlight to obtain a set of DBpedia entities.
In the same way, we find entities from the terms of the query.
From this set of entities and through queries to a DBpedia SPARQL endpoint, we obtain a graph by finding all the relationships between the entities.
To each entity, we associate a text obtained by merging its DBpedia’s abstract and windows of text from the webpage centered on the surface forms associated with the entity.
With as input the graph, its associated text, and the entities extracted from the query, we execute LDRANK and we obtain a ranking of the entities.
The top-ranked entities (viz. “main-entities”) are displayed on the snippet.
From a DBpedia SPARQL endpoint, we do a 1-hop extension of the main-entities in order to increase the number of triples among which we will then search for the more important ones in terms of a link analysis of the graph.
To do this, we build a 3-way tensor from the extended graph: each predicate corresponds to an horizontal slice that represents the adjacency matrix for the restriction of the graph to this predicate.
We compute the PARAFAC decomposition of the tensor into a sum of factors (rank-one three-way tensors):
for each main-entity, we select the factors to which it contributes the most (as a subject or as an object), and for each of these factors we select the triples with the best ranked predicates.
Thus, we associate to each main-entity a set of triples that will appear within its description.
Finally, we used a machine learning approach to select short excerpts of the webpage to be part of the description of each main-entity. We designed a number of features based on the query, the text of the webpage, and the ranked entities.
For the feature selection process, we used an infogain metric to select a small set of features then used as a starter-set for a wrapper method with a forward selection approach.
We observed that the features derived from the LDRANK ranking remained in the set of used features, which stands as a supplementary, although indirect, element in favor of the usefulness of LDRANK.
LDRANK (Linked Data Ranking Algorithm)
We introduce LDRANK (Linked Data Ranking Algorithm), a quey-biased algorithm for ranking the entities of a RDF graph. LDRANK is well adapted to sparse graphs for which textual data can be associated with the nodes. Indeed, LDRANK uses both the explicit structure of the graph and the implicit relationships that can be inferred from the text of the nodes.
- LDRANK v0.9 source code under GPL licence
Main experiments and results
Grants
- A franco-german grant for the thesis of Mazen Alsarem in the context of the MDPS doctoral college
Selected publications
- [1] Mazen Alsarem, Pierre-Edouard Portier, Sylvie Calabretto and Harald Kosch. Making use of linked data for generating enhanced snippets. In ESWC 2014 demo track. http://liris.cnrs.fr/publis/?id=6672 (PDF)
- [2] Mazen Alsarem, Pierre-Edouard Portier, Sylvie Calabretto and Harald Kosch. Ranking Entities in the Age of Two Webs, An Application to Semantic Snippets. In ESWC 2015. (PDF)
- [3] Mazen Alsarem, Pierre-Edouard Portier, Sylvie Calabretto and Harald Kosch. Ordonnancement d'entités pour la rencontre du Web des documents et du Web des données. In Document Numérique 2015. To be published. (PDF)
Events and Presentations
2015/10/02: Linked Data as a source of prior knowledge, the case of LDRANK
2015/06/03: Mazen presenting our work at ESWC 2015 (slides and corresponding paper) !

