Web of Data / Web of Documents: Experiments and results
- Dataset for Evaluating Query-biased Ranking of LOD entities
- Data Collection
- Queries:
- We took randomly 30 queries from the “Yahoo! Search Query Tiny Sample” offered by Yahoo! Webscope
- Documents:
- We submitted the queries to the Google search engine and we kept the top-5 Web pages for each query (==> 150 HTML Web pages).
- We extracted the text of each page.
- Finally, we annotated each text using DBpedia Spotlight.
- Queries:
- CrowdSourcing
- MicroTasks
- Considering the length of our texts, the task of evaluating all the annotations of a Web page would be too demanding. Therefore, we divide this task into smaller“microtasks”. A microtask will consist in scoring the relevance of the annotations of a single sentence.
- We used the CrowdFlower crowdsourcing platform.
- Quality Control
- Workers had a maximum of 30 minutes to provide an answer.
- Workers had to spend at least 10 seconds on the job before giving an answer.
- We measured the agreement between workers with the Krippendorff’s alpha coefficient.
- To improve the quality of our dataset, we removed the workers that often disagreed with the majority.
- MicroTasks
- Aggregation of the Results
- We used majority voting for aggregating the results inside each sentence.
- We used the same majority voting strategy to aggregate the results at the level of a Web page.
- Data
- Resource Ranking
- Algorithms
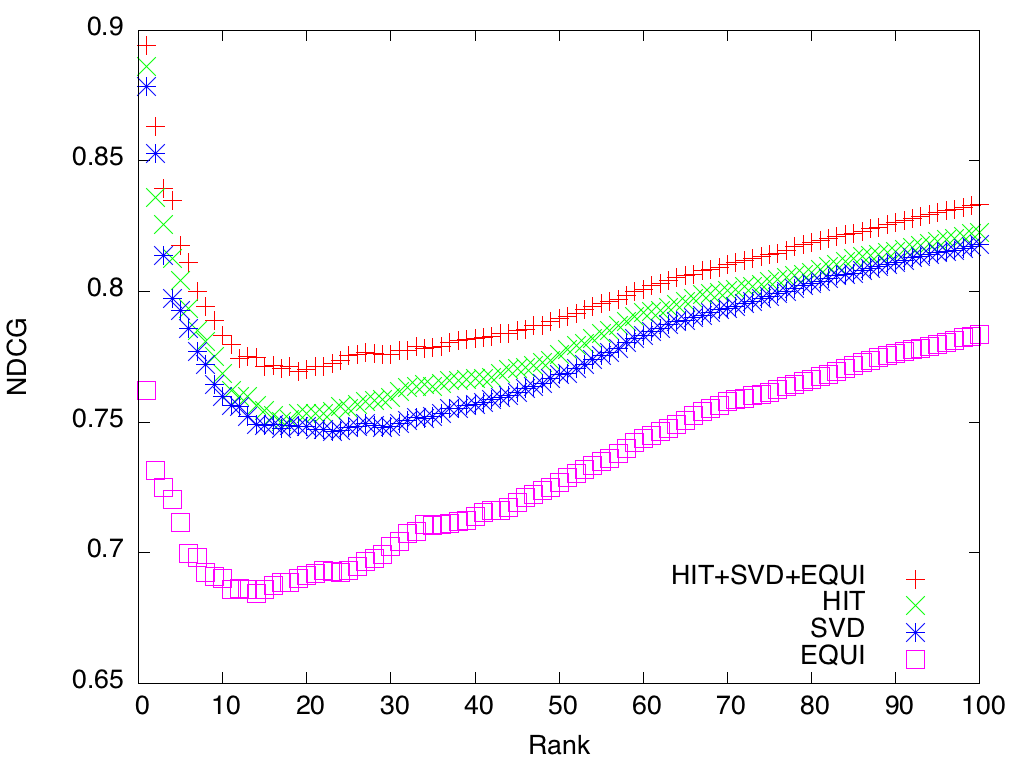
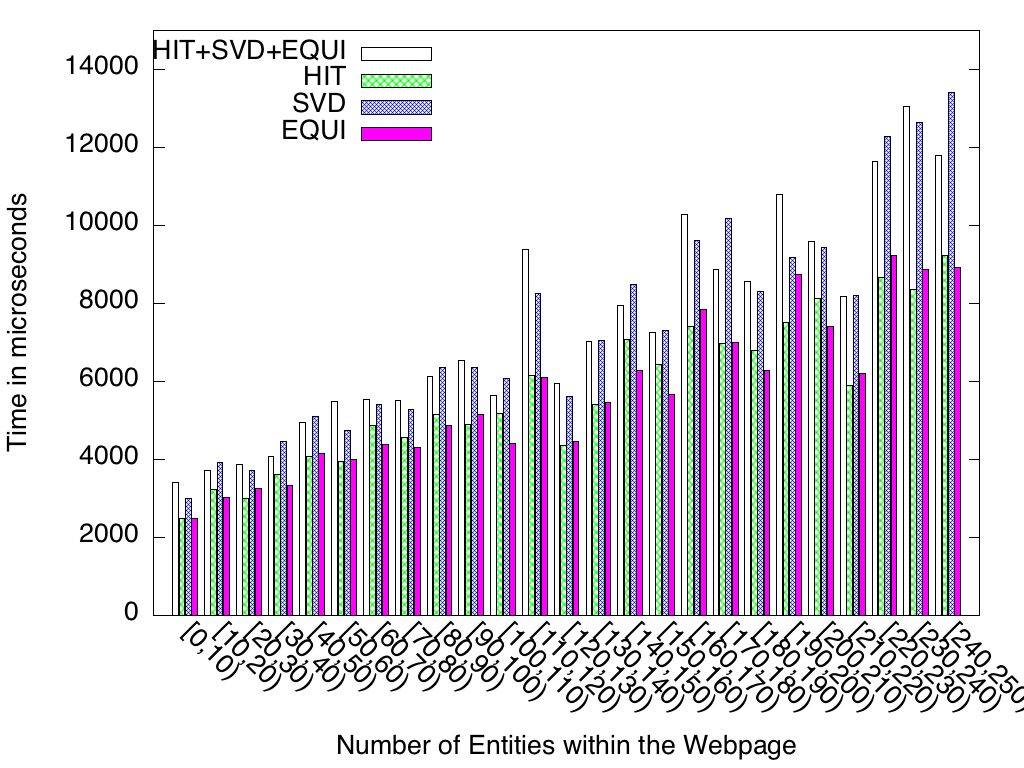
- LDRANK v0.9 source code under GPL licence ; it contains the four algorithms being compared in this work (i.e., (i) LDRANK (labeled "HIT+SVD+EQUI" on the graphs below), (ii) the algorithm proposed by Fafalios and Tzitzikas (labeled "HIT" on the graphs below), (iii) a new algorithm based on the SVD decomposition (labeled "SVD" on the graphs below), and (iii) a basic PageRank (labeled "EQUI" on the graphs below))
- Dataset obtained from crowdsourcing and used to compare the algorithms
- Results:
- You can download the scripts that have been used to generate the performance and efficiency results given the algorithms and the dataset (you could start by looking at the script named "go.sh").
- You can download the scripts that have been used to generate the performance and efficiency results given the algorithms and the dataset (you could start by looking at the script named "go.sh").
- Sentence Selection
- Full technical report
- Download datasets:
- Original datasets
- Datasets after resolving the unbalanced classes problem (using the SMOTE filter)
- Used softwares:
Results:
results using all the features
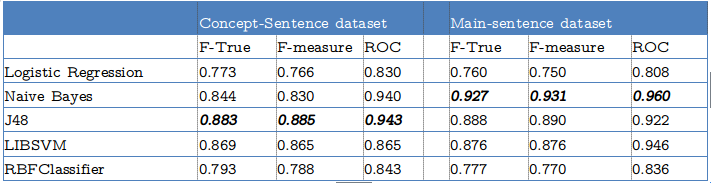
machine learning performance results over main-sentence dataset (using features selection)
We apply InfoGain filter to select the start subset (first line), then we apply a forward Naive Bayes wrapper (second line), finally we measure the prediction performance using 10 fold cross validation, and F measure.

machine learning performance results over concept-sentence dataset (using features selection)
We apply InfoGain filter to select the start subset (first line), then we apply a forward J48 wrapper (second line), finally we measure the prediction performance using 10 fold cross validation, and F measure.

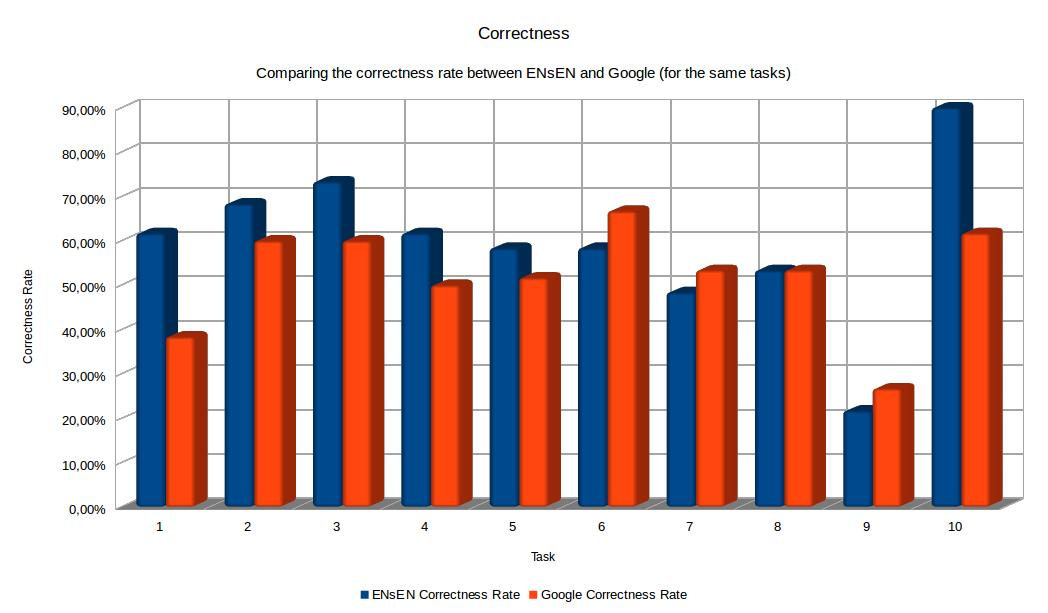
- ENsEN: Crowdsourcing-based User Evaluation
- We selected randomly 10 tasks from the “Yahoo! Answers Query To Questions” dataset.
- Each task was made of three questions on a common topic.
- To each task corresponds a job on the CrowdFlower platform.
- We collected 20 judgments for each task.
- Half of the workers was asked to use our system, and the other half used Google.
- In order to control that a worker answered the task by using our system, we generated a code that the worker had to copy and paste into her answer.
- Only complete answers were considered correct.
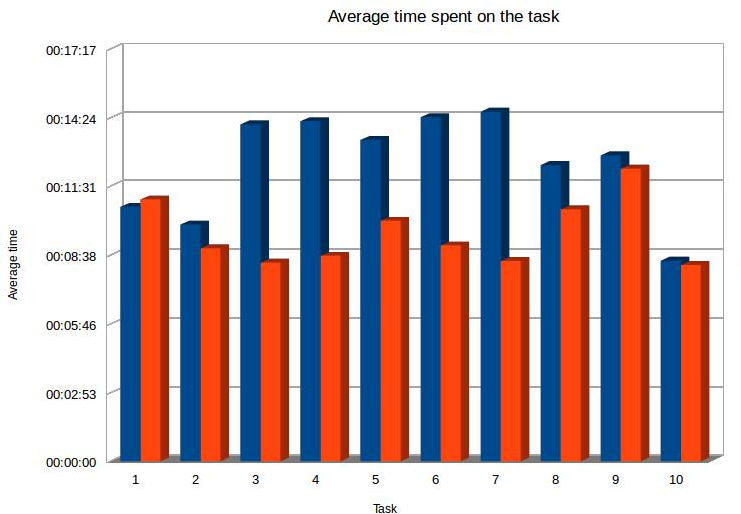
- We also monitored the time spent to answer the tasks. Thus, ENsEN is clearly beneficial to its users in terms of usefulness.