

In this project, we integrate multiple stage depth induced contextual information for human action recognition and detection. The processing pipeline is given in the following diagram. First, we employ HOG based human key pose and object detector to detect humans and objects in every input frame. Depth information is used to filter out large numbers of false detections. Then the detected results are temporally matched and tracked throughout frames and depth constraints are further utilized to filter out invalid tracklets. Then these tracklets of human key poses and objects are used for modeling spatial temporal interaction attibutes. On the meantime, depth information is utilized for classifying scene into different scene types. The obtained spatial temporal interaction attributes as well as the scene classification results are fused together via a Bayesian network for final detection and localization of certain actions.
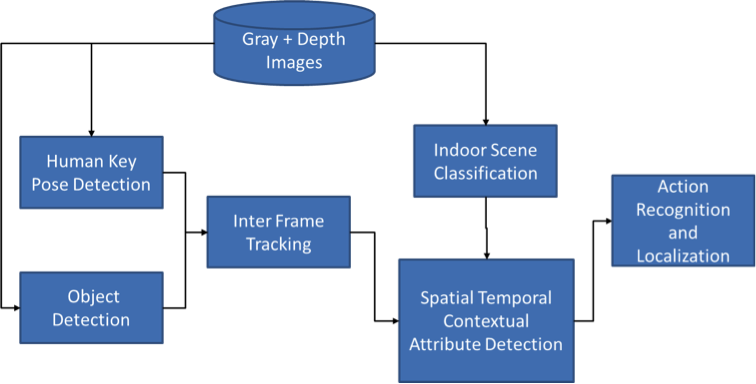
We employ histogram of oriented gradient (HOG) detector for human and object detection. The key pose types are defined by clustering the given ground truth annotations into different key poses via K-means algorithm. Totally we detect 29 types of key poses. For object, we detect 3 types of object. The detection is performed on the grey level image only. Once we get the candidate detection, we apply depth constraints to removal false alarms. These constraints include the area/median depth ratio for a human subject, and the rule that human body depth should be nearer than the body surrounding depth values. Large number of false detections could be removed using these heuristic constraints. Once the detection results at every frame is obtained, we match and track the detections throughout frames by measuring the spatial distance and mean grey values, and matched detections are formed into tracklets including humans and objects. The tracklets with temporal length smaller than some threshold value are further removed.
When the tracklets are obtained, we further model the interaction between tracklets (including human - human and human - object). And we define a set of 4D (XYZT) interaction attributes. These attributes include: 1) average 3D spatial displacement between two tracklets; 2) average 3D spatial motion speed between two tracklets; 3) tracklet A temporally precedes tracklet B; 4) tracklet A temporally succeeds tracklet B; 5) tracklet A temporally contains tracklet B; 6) temporal overlap between two tracklets, etc.
To model the geometric attributes of the scene, we transform the depth image into normal map. Normal map is composed of values of each cell plane's (patch) 3D normals. Normal is a normalized vector that indicates the orientation of a plane. For each pixel in depth map, we use its neighbour pixels' 3D coordinates to fit a panel, and compute the panels' normals. We use a 7X7 window to get each pixel's neighbour pixels. After calculating the normals, we represent the scene by four major orientations (up, down, left, right) and using its orientation histogram to classify the scene type by support vector machine.
After obtaining the key pose types of the tracklets, the interaction attributes and the scene types, we use a Bayesian network for inferring the action label. The input are the key pose type, interaction attributes and scene type. The output is the action label. The inferred action is further localized by giving the bounding box tightly contains the involved tracklets.
We have attempted the recognition of Human activities using segmentation based supervised approach. At this stage we have not tried to solve the localization problem of HARL . Our approach is broadly divided into two modules. First is the segmentation of object of interest from the background which, we think, could be discarded for recognition purpose. In the second module motion based features are estimated to train a classifier and then recognize a query HARL activity.
In this module, we detect moving objects in a (video) sequence of images. Here, motion based segmentation has been applied to isolate background from the object of interest. One limitation of motion based segmentation occurs in case of camera motion/jitter. We have handled that issue by detecting the sequence of frames captured without moving the camera and process the frames within this sequence. In case statistically significant number of pixel values deviates from the mean pixel values for some consecutive frames, the source of the deviation is considered as due to the change in camera motion or jitter or sudden illumination change.
The background estimation rests on the premise that background is more prevalent in a frame and it does not change as frequently as the object of interest. Given a set of image frames in sequence, the difference of median pixel values of the sequence with respect to individual pixel is calculated. If the difference value is greater than a threshold, the particular pixel value is considered as a part of the object. More sophisticated technique may be applied but we have seen that this relatively simple approach works fine as the speeds of object of interest are moderate with respect to the frame speed in the HARL database and there is not any quick and significant illumination change. Very Small and very large connected components are eliminated based on area based morphological techniques. Entropy of remaining connected components is evaluated. The entropy of connected components is evaluated considering the variation of pixel values (contained in the connected component) . The assumption is that the object of interest should represent busy pixel regions over a time period signifying higher uncertainty or pixel disorder. Based on the entropy value, a set of connected components is selected to contain objects of interest and subjected to further processing as follows.
We have already depth image with gray level image. And now depth information will play crucial role for estimating depth connectivity. Whether two neighbor pixels in a visual image are in the same plan is tested after checking the depth image. Assume, the distance between one pixel to another pixel is a threshold distance and it is called as a depth in our approach. And it is only constraint for connectivity between target pixel and its 8 adjoining pixels. Based on this threshold, we will be calculating value of final image. The distance above this limit will be consider as component with discontinuity in edge. Component with lower number of edge will be eliminated for finding final segmentation and localization . In the next section, we explain how features are evaluated on the segmented image.
The proposed feature descriptor is applied on the bounding box of the connected components estimated in the last section. The features are organized in a fashion similar to the Histogram of Oriented Optical Flow (HOOF) [2] calculated in a multiresolution framework. The features are estimated on the entire image and also on the sub-sampled image at three levels in a pyramidal architecture. The features of the full image capture global pattern while features at every (quadtree based) sub-region of the image capture local variation. The optic flow vectors are pre-processed with the edge magnitude of images so that the optic flow only at the significant object contours dominates HOOF. The orientation of the gradient weighted optic flow is quantized in only 8 directions. To capture local motion and enhance performance of recognition, we have added time as 4th dimension to this approach. For each block, we will be computing the difference of current block and next block. This dissimilarity is assumed as local motion of object. Finally, there is a 189 dimensional descriptor to track fine detail of human activity.
[1] Guillaume Lemaitre, "Image Analysis: Mean-Shift Tracking", http://g.lemaitre58.free.fr/pdf/vibot/tracking/Guillaume_Lemaitre_Mean_Shift.pdf (last accessed on 7th September, 2012.)
[2] Snehasis Mukherjee, Sujoy Kumar Biswas, Dipti Prasad Mukherjee, "Recognizing Human Action at a Distance in Video by Key Poses", IEEE Transactions on Circuits and Systems for Video Technology, vol. 21, no. 9, pp. 1228-1241, 2011
System description not available.
We have extracted STIPs, where every STIP consists of 162-demensional feature(HOG and HOF) with method [1]. Then we train 10 one-against-all SVM classifiers for 10 activity categories using STIPs from previous step.
We extract STIPs and classify them with the trained SVMs. Localization is done using a variant of the technique in [2] on subvolume Mutual Information Maximization, which we adapted to our needs. We reduced the searching bound according to positive mutual information and set a proper step width, so the searching algorithm is much faster than the brute force search.
[1] Ivan Laptev, "On Space-Time Interest Points", International Journal of Computer Vision, 64(2-3):107-123, 2005.
[2] Junsong Yuan, Zicheng Liu and Ying Wu, "Discriminative subvolume search for efficient action detection ", International Conference on Computer Vision and Pattern Recognition, 2009.