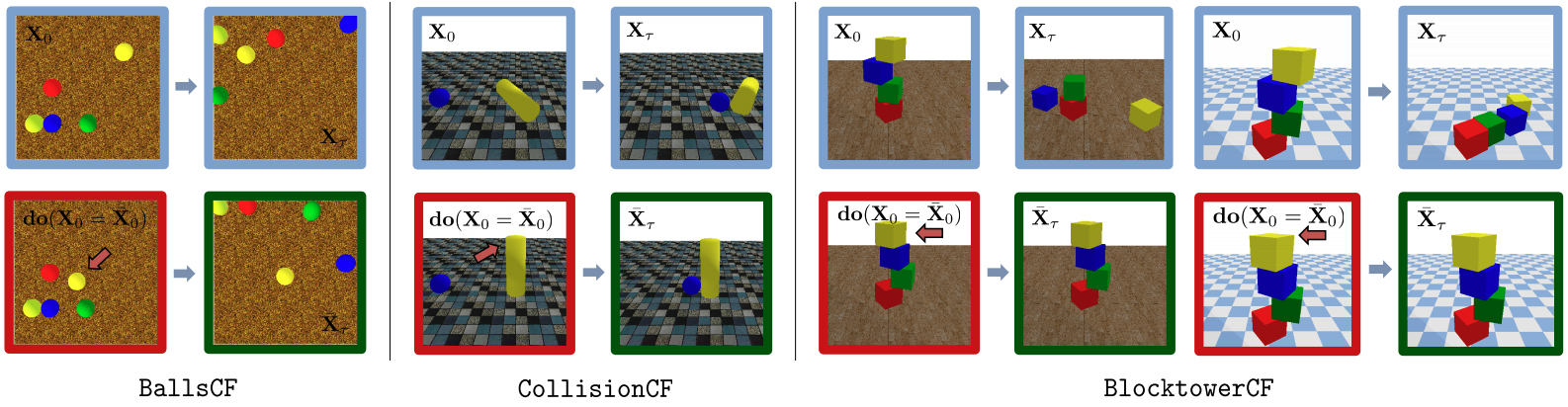
We introduce the Counterfactual Physics benchmark suite (COPHY) for counterfactual reasoning
of physical dynamics from raw visual input. It is composed of three tasks based on three physical
scenarios: BlocktowerCF, BallsCF and CollisionCF, defined similarly to existing state-ofthe-art environments for learning intuitive physics: Shape Stack (Groth et al., 2018), Bouncing balls
environment (Chang et al., 2017) and Collision (Ye et al., 2018) respectively. This was done to ensure
natural continuity between the prior art in the field and the proposed counterfactual formulation.
Each scenario includes training and test samples, that we call experiments. Each experiment is
represented by two sequences of synthetic RGB images (covering the time span of 6 sec at 4 fps):
-
an observed sequence demonstrates evolution of the dynamic system under the
influence of laws of physics (gravity, friction, etc.), from its initial state to its final state. For
simplic ity, we denote A the initial state and B the observed outcome;
-
a counterfactual sequence with an initial state C after the do-intervention, and the counterfactual outcome D.
A do-intervention is a visually observable change introduced to the initial physical setup (such
as, for instance, object displacement or removal).
Finally, the physical world in each experiment is parameterized by a set of visually unobservable
quantities, or confounders (such as object masses, friction coefficients, direction and magnitude of
gravitational forces), that cannot be uniquely estimated from a single time step. Our dataset provides
ground truth values of all confounders for evaluation purposes. However, we do not assume access to
this information during training or inference, and do not encourage it.
Each of the three scenarios in the COPHY benchmark is defined as follows.
BlocktowerCF
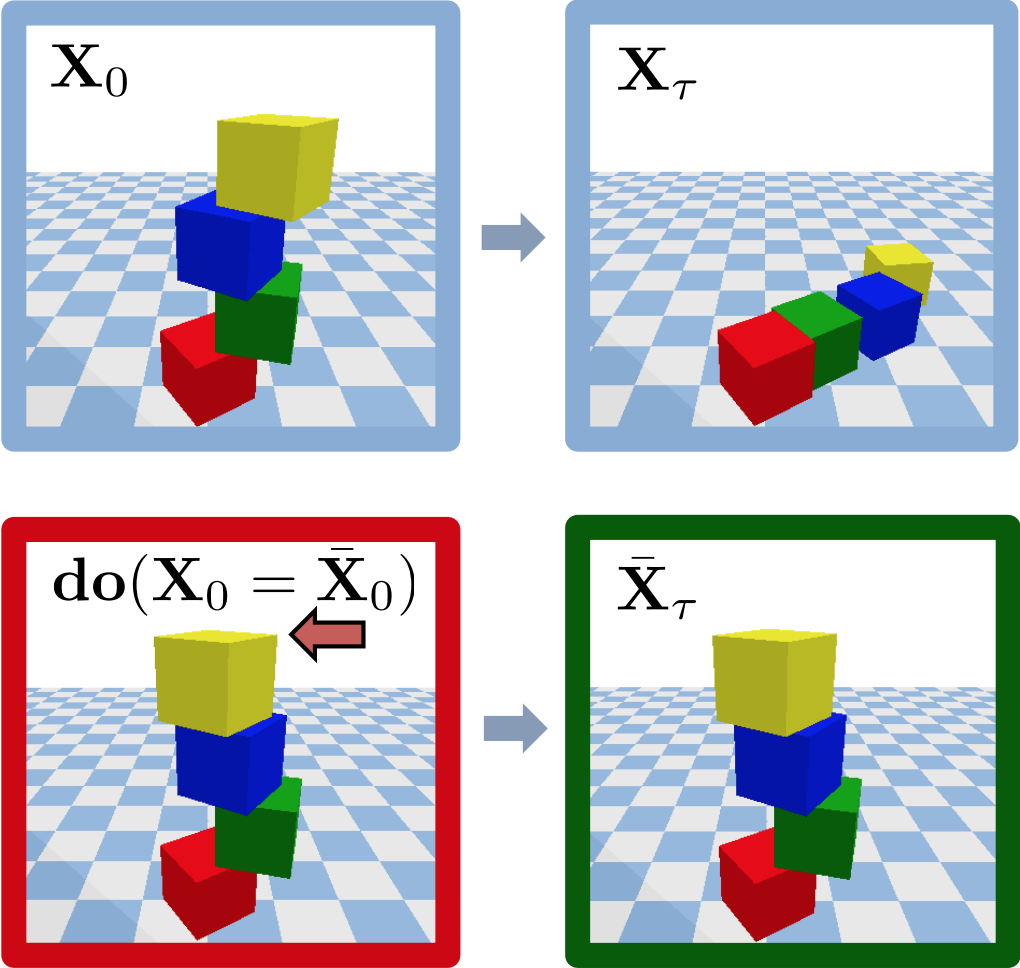
Each experiment involves K=3 or K=4 stacked cubes, which are initially at
resting (but potentially unstable) positions. We define three different confounder variables:
masses, m∈{1, 10} and friction coefficients, µ∈{0.5, 1}, for each block, as well as gravity
components in X and Y direction, gx,y∈{−1, 0, 1}. The do-interventions include block
displacement or removal. This set contains 146k sample experiments corresponding to 73k
different geometric block configurations.
BallsCF
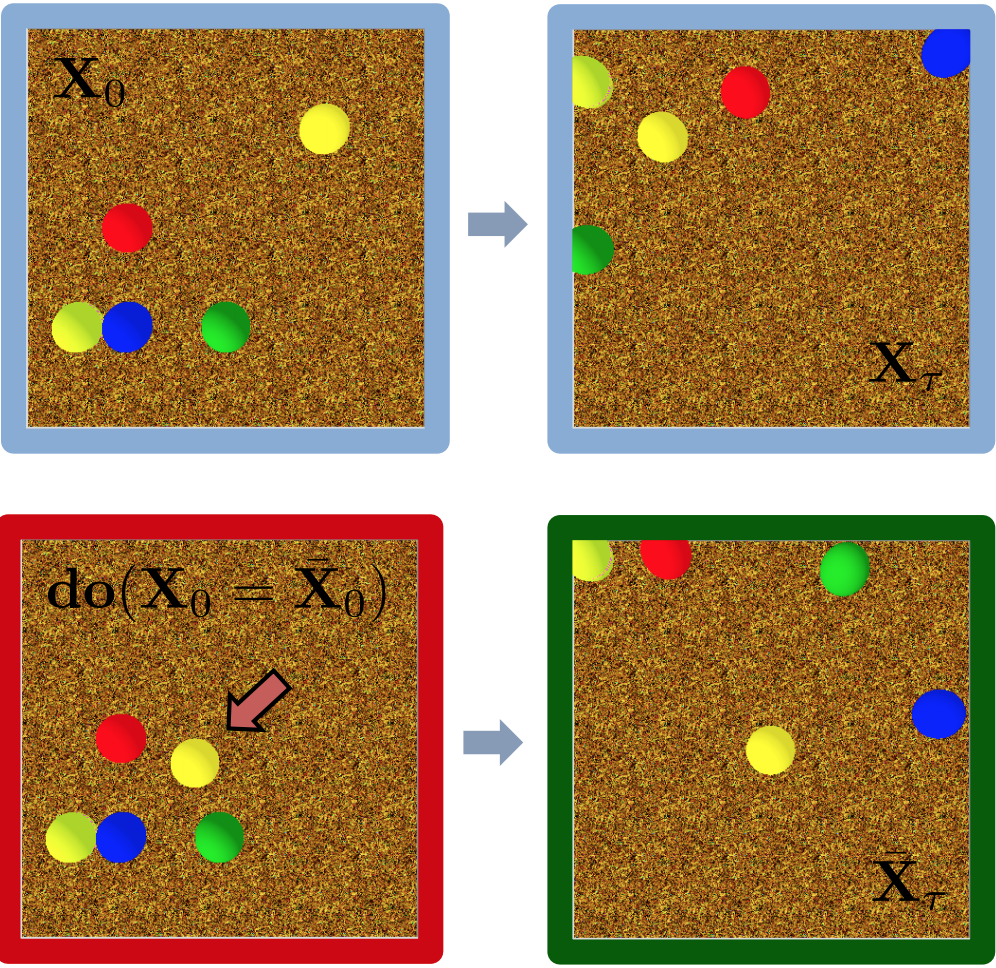
Experiments show K bouncing balls (K=2…6). Each ball has an initial random
velocity. The confounder variables are the masses, m∈{1, 10}, and the friction coefficients,
µ∈{0.5, 1}, of each ball. There are two do-operators: block displacement or removal. There
are in total 100k experiments corresponding to 50k different initial geometric configurations.
CollisionCF
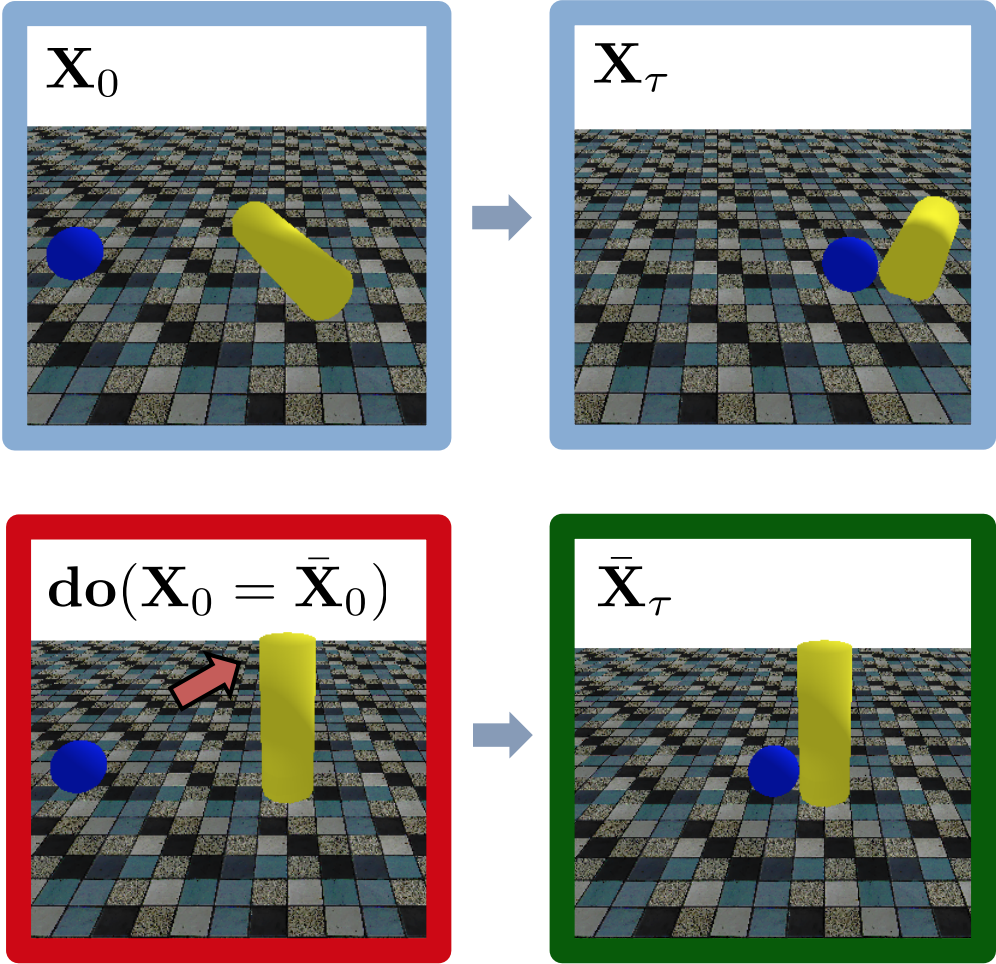
This set is about moving objects colliding with static objects (balls or cylinders). The confounder variables are the masses, m∈{1, 10}, and the friction coefficients,
µ∈{0.5, 1}, of each object. The do-interventions are limited to object displacement. This
scenario includes 40k experiments with 20k unique geometric object configurations.
Usage
Given this data, the problem can be formalized as follows. During training, we are given the
quadruplets of visual observations A, B, C, D, but do not not have
access to the values of the confounders. During testing, the objective is to reason on new visual data
unobserved at training time and to predict the counterfactual outcome D, having observed the first
sequence (A, B) and the modified initial state C after the do-intervention, which is known.
The COPHY benchmark is by construction balanced and bias free w.r.t. (1) global statistics of all
confounder values within each scenario, (2) distribution of possible outcomes of each experiment
over the whole set of possible confounder values (for a given do-intervention). We make sure that the
data does not degenerate to simple regularities which are solvable by conventional methods predicting
the future from the past. In particular, for each experimental setup, we enforce existence of at least
two different confounder configurations resulting in significantly different object trajectories. This
guarantees that estimating the confounder variable is necessary for visual reasoning on this dataset.
More specifically, we ensure that for each experiment the set of possible counterfactual outcomes is
balanced w.r.t. (1) tower stability for BlocktowerCF and (2) distribution of object trajectories for
BallsCF and CollisionCF. As a result, the BlocktowerCF set, for example, has 50 ± 5% of
stable and unstable counterfactual configurations.
The exact distribution of stable/unstable examples for each confounder in this scenario is shown below:

All images for this benchmark have been rendered into the visual space (RGB, depth and instance
segmentation) at a resolution of 448 × 448 px with PyBullet (only RGB images are used in this work).
We ensure diversity in visual appearance between experiments by rendering the pairs of sequences
over a set of randomized backgrounds. The ground truth physical properties of each object (3D pose,
4D quaternion angles, velocities) are sampled at a higher frame rate (20 fps) and also stored. The
training / validation / test split is defined as 0.7 : 0.2 : 0.1 for each of the three scenarios