RED: Rich Epinions Dataset for Recommender Systems
Recommender Systems require specific datasets to evaluate their approach. They do not require the same information: descriptions of users or items or users interactions may be necessary, which is not gathered in today datasets.
This site provides a dataset extracted from Epinions in June 2011. It contains reviews from users on items, trust values between users, items category, categories hierarchy and users expertise on categories. This dataset can be used to evaluate various Recommender Systems using Collaborative Filtering, Content-Based or Trust-Based.
More details about the RED dataset are available in this publication.
The RED development project is now terminated and we do not have the full version of the dataset any more. Therefore, we cannot provide supplementary data from what is already downloadable from this site (despite what is written in the publications). We apologize about that.
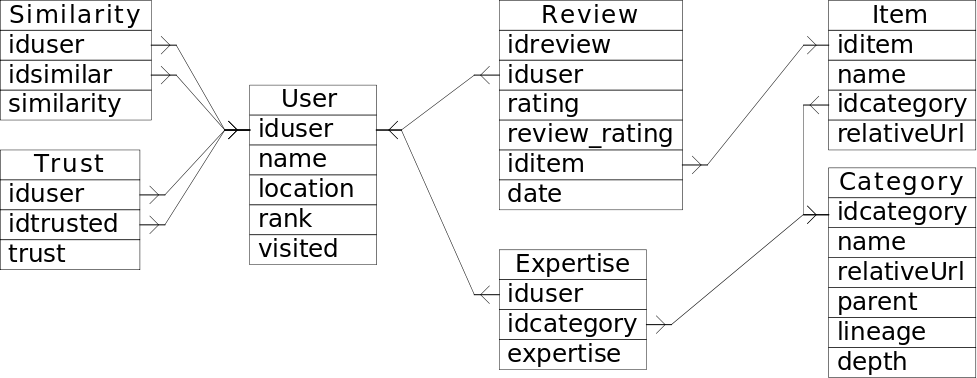
Structure
The dataset is a relational database with the following tables:
- User: name (pseudo and profile url), location, top rank (may be null) and profile visits count
- Item: name, category and profile url
- Category: name, parent category, description url, lineage (path in the category tree) and depth (in the category tree)
- Review: a review associates a user with an item, it contains the rating, between 1 and 5, the review rating (mean of all review ratings associated with this review) and the review date
- Expertise: users who are experts in a category appear here with the expertise (category lead, top reviewer, advisor) associated with the considered category
- Trust: web of trust, i.e. a trust value (either -1 or 1) from one user to another, only positive trust values appear in the dataset
- Similarity: we have computed the similarity between all users couples using the Pearson coefficient correlation. Since this operation may be long and is used in classical collaborative filtering, we provide it in order to ease recommendation; those values do not belong to the Epinions website
How to use the dataset
The dateset is distributed under the following licence:
Rich Epinions Dataset by Simon Meyffret, Frédérique Laforest and Lionel Médini is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
Based on a work at http://liris.cnrs.fr/red/#download.
Permissions beyond the scope of this license may be available at http://liris.cnrs.fr/red/#license.
Download the dataset
Here it is:
How to contact us
You can ask for more details at red[at]liris.cnrs.fr.
Thank you not to contact us to ask for an extended version of the dataset, as we do not have it any more.
