Conférences internationales avec comité de lecture (3)
LudovicMoncla, DenisVigier & KatherineMcdonough (2024). « GeoEDdA: A Gold Standard Dataset for Geo-semantic Annotation of Diderot & d'Alembert's Encyclopédie ». Second International Workshop on Geographic Information Extraction from Texts (GeoExT) to be held at the 46th European Conference on Information Retrieval (ECIR 2024), 24 mars 2024, Glasgow (Royaume-Uni).HAL : hal-04511909. .
YoucefRemil, AnesBendimerad, RomainMathonat, ChedyRaïssi & MehdiKaytoue (2024). « DeepLSH: Deep Locality-Sensitive Hash Learning for Fast and Efficient Near-Duplicate Crash Report Detection ». IEEE/ACM International Conference on Software Engineering, 20 avril 2024, Lisbon (Portugal) (Portugal).HAL : hal-04236085. .
JiyunBeak & LudovicMoncla (2024). « Mapping Global Protest Tendencies: Geolocating Trends and Topics Through Wikipedia Analysis ». Second International Workshop on Geographic Information Extraction from Texts (GeoExT), 24 mars 2024, Glasgow (Royaume-Uni).HAL : hal-04511913. .
HDR, thèses (1)
Thèses (1)
LéonardTschora (2024). « Machine Learning techniques for Electricity Price Forecasting ». HAL : tel-04372073. .
RémyCazabet, SalvatoreCitraro & GiulioRossetti (2023). « Structify-Net: Random Graph generation with controlled size and customized structure ». Peer Community Journal, vol.3, e103. doi : 10.24072/pci.networksci.100114. HAL : hal-04424059. .
YassineHmidy, AgnèsRico & OlivierStrauss (2023). « Macsum aggregation learning ». Fuzzy Sets and Systems, vol.459, pp.182-200. doi : 10.1016/j.fss.2022.10.014. HAL : hal-03837063. .
Dou El KefelMansouri, KhalidBenabdeslem, Seif-EddineBenkabou, SouleymanChaib & MohamedChohri (2023). « mFILS: Tri-Selection via Convex and Nonconvex Regularizations ». IEEE Transactions on Neural Networks and Learning Systems, pp.1-14. doi : 10.1109/TNNLS.2023.3237170. HAL : hal-03955074.
LouisDuvivier, RémyCazabet & CélineRobardet (2023). « Graph model selection by edge probability prequential inference ». Journal of Complex Networks. doi : 10.1093/comnet/cnad011. HAL : hal-04355823.
Dou El KefelMansouri, Seif-EddineBenkabou, KhaoulaMeddahi, AllelHadjali, AminMesmoudi, KhalidBenabdeslem & SouleymanChaib (2023). « CoSP: co-selection pick for a global explainability of black box machine learning models ». World Wide Web, vol.26, n°6, pp.3965-3981. doi : 10.1007/s11280-023-01213-8. HAL : hal-04450994.
NatkamonTovanich & RémyCazabet (2023). « Fingerprinting Bitcoin entities using money flow representation learning ». Applied Network Science, vol.8, n°1, p.63. doi : 10.1007/s41109-023-00591-2. HAL : hal-04208864. .
Conférences (19)
Conférences internationales avec comité de lecture (18)
LéonardTschora, TiasGuns, ErwanPierre, MarcPlantevit & CelineRobardet (2023). « Electricity Price Forecasting based on Order Books: a differentiable optimization approach ». 2023 IEEE 10th International Conference on Data Science and Advanced Analytics (DSAA), 13 octobre 2023, Thessaloniki (Grèce).doi : 10.1109/DSAA60987.2023.10302542. HAL : hal-04345460. .
TimothéeChane-Haï, SamuelVercraene, CélineRobardet & ThibaudMonteiro (2023). « Improving the non-urgent sanitary transportation ». 7th International Conference on Control, Automation and Diagnosis (ICCAD 2023), 12 mai 2023, Rome (Italie).doi : 10.1109/ICCAD57653.2023.10152350. HAL : hal-04423051. .
LoujainLiekah, HaythamElghazel, FabienDe Marchi & Mohand-SaïdHacid (2023). « Clustering Multivariate Longitudinal Data Application on Disease Progression Modeling ⋆ ». Modeling Decisions for Artificial Intelligence, 22 juin 2023, UMEÅ (Suède).HAL : hal-04097278. .
FlorianBaud & AlexAussem (2023). « Résumé automatique multi-documents guidé par une base de résumés similaires ». 18e Conférence en Recherche d'Information et Applications -- 16e Rencontres Jeunes Chercheurs en RI -- 30e Conférence sur le Traitement Automatique des Langues Naturelles -- 25e Rencontre des Étudiants Chercheurs en Informatique pour le Traitement Automatique des Langues, Paris (France), pp.19-27. HAL : hal-04130224. .
LudovicMoncla & MauroGaio (2023). « Perdido : librairie Python pour le geoparsing et le geocoding de textes en français ». Extraction et Gestion des Connaissances (EGC'2023), 20 janvier 2023, Lyon (France).HAL : hal-03928358. .
LudovicMoncla & MauroGaio (2023). « Perdido: Python library for geoparsing and geocoding French texts ». First International Workshop on Geographic Information Extraction from Texts (GeoExT), 2 avril 2023, Dublin (Irlande).HAL : hal-04049794. .
FlorianBaud & AlexAussem (2023). « Non-Parametric Memory Guidance for Multi-Document Summarization ». International Conference Recent Advances in Natural Language Processing (RANLP), 6 septembre 2023, Varna (Bulgarie).ArXiv : 2311.10760. HAL : hal-04281841. .
FlorianBaud & AlexAussem (2023). « Answering Student Queries with a Supervised Memory Conversational Agent ». The International FLAIRS Conference Proceedings (FLAIRS-36), 17 mai 2023, Clearwater Beach (États-Unis).doi : 10.32473/flairs.36.133195. HAL : hal-04249196. .
DanielaMariño, LudovicMoncla & RossPurves (2023). « Extracting positive descriptions and exploring landscape value using text analysis in the Cairngorms National Park ». 7th ACM SIGSPATIAL International Workshop on Geospatial Humanities, 13 novembre 2023, Hamburg (Allemagne), pp.44-47. doi : 10.1145/3615887.3627758. HAL : hal-04274439.
RémyCazabet, CatherineAnnen, Jean-FrançoisMoyen & RobertoWeinberg (2023). « A toy model for approaching volcanic plumbing systems as complex systems ». 3rd French Regional Conference on Complex Systems (FRCCS 2023), 2 juin 2023, Le Havre (France).HAL : hal-04166088. .
YasamanAsgari, RémyCazabet & PierreBorgnat (2023). « Mosaic benchmark networks: Modular link streams for testing dynamic community detection algorithms ». Complex Networks And Applications 2023, 30 novembre 2023, Menton (France).doi : 10.48550/arXiv.2310.02840. ArXiv : 2310.02840v1. HAL : hal-04236873. .
YacineGaci, BoualemBenatallah, FabioCasati & KhalidBenabdeslem (2023). « Targeting the Source: Selective Data Curation for Debiasing NLP Models ». European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases, Torino (France), pp.276-294. doi : 10.1007/978-3-031-43415-0_17. HAL : hal-04450752.
RafaelRamos Tubino, RémyCazabet, NatkamonTovanich & CélineRobardet (2023). « Temporal and Geographical Analysis of Real Economic Activities in the Bitcoin Blockchain ». LIMBO@ECML/PKDD 2023: International workshop on LearnIng and Mining for BlOckchains, 18 septembre 2023, Turin (Italie).HAL : hal-04188062. .
YoucefRemil, AnesBendimerad, MathieuChambard, RomainMathonat, MarcPlantevit & MehdiKaytoue (2023). « Mining Java Memory Errors using Subjective Interesting Subgroups with Hierarchical Targets ». IEEE International Conference on Data Mining Workshops (ICDM Workshops), 4 décembre 2023, Shanghai (Chine) (Chine).HAL : hal-04224279. .
ThomasRanvier, HaythamElghazel, EmmanuelCoquery & KhalidBenabdeslem (2023). « Considération de l'Incertitude d'Imputation pour l'Apprentissage des Réseaux de Neurones ». Plate-Forme Intelligence Artificielle (PFIA 2023), 7 juillet 2023, Strasbourg (France).HAL : hal-04227951. .
AliceBrenon, DenisVigier, LudovicMoncla & FrederiqueLaforest (2023). « Comparaison diachronique de motifs récurrents dans deux encyclopédies ». 11e Journées Linguistique de Corpus, 8 juin 2023, Grenoble (France).HAL : hal-04146494. .
HDR, thèses (2)
Thèses (2)
YoucefRemil (2023). « A data mining perspective on explainable AIOps with applications to software maintenance ». HAL : tel-04391281. .
LucaVeyrin-Forrer (2023). « Explaining machine learning models on graphs by identifying hidden structures built by GNNs ». HAL : tel-04214965. .
RémyCazabet & GiulioRossetti (2023). « Challenges in Community Discovery on Temporal Networks ». Temporal Network Theory, Springer International Publishing, pp.185-202. doi : 10.1007/978-3-031-30399-9_10. ArXiv : 1907.11435. HAL : hal-04447833.
RémyCazabet, JacquesFize, SalvatoreCitraro & GiulioRossetti (2023). « Beyond space and blocks: Generating networks with arbitrary structure ». International School and Conference on Network Science 2023, 14 juillet 2023, Vienne (Autriche). Poster. HAL : hal-04441398. .
FlorianBaud & AlexAussem (2023). « Répondre aux requêtes des étudiants avec un agent conversationnel à mémoire supervisée ». Extraction et Gestion des Connaissances, 20 octobre 2023, Lyon (France). Poster. HAL : hal-04249159. .
LudovicMoncla, BrunoMartins, KatherineMcdonough & XukeHu (2023). « GeoHumanities '23: Proceedings of the 7th ACM SIGSPATIAL International Workshop on Geospatial Humanities ». doi : 10.1145/3615887. HAL : hal-04276547.
Revues internationales avec comité de lecture (14)
MaëlleMoranges, MarcPlantevit & MoustafaBensafi (2022). « Using subgroup discovery to relate odor pleasantness and intensity to peripheral nervous system reactions ». IEEE Transactions on Affective Computing, pp.1-1. doi : 10.1109/TAFFC.2022.3173403. HAL : hal-03787352. .
OlivierStrauss, AgnèsRico & YassineHmidy (2022). « Macsum: A new interval-valued linear operator ». International Journal of Approximate Reasoning, vol.145, pp.121-138. doi : 10.1016/j.ijar.2022.03.003. HAL : hal-03837036. .
KhalidBenabdeslem, Dou El KefelMansouri & RaywatMakkhongkaew (2022). « sCOs: Semi-Supervised Co-Selection by a Similarity Preserving Approach ». IEEE Transactions on Knowledge and Data Engineering, vol.34, n°6, pp.2899-2911. doi : 10.1109/TKDE.2020.3014262. HAL : hal-04451716.
AliceBrenon, LudovicMoncla & KatherineMcdonough (2022). « Classifying encyclopedia articles: Comparing machine and deep learning methods and exploring their predictions ». Data and Knowledge Engineering, vol.142, p.102098. doi : 10.1016/j.datak.2022.102098. HAL : hal-03821073. .
NazhaSelmaoui-Folcher, JannaïTokotoko, SamuelGorohouna, LaisaRoi, ClaireLeschi & CatherineRis (2022). « Concept of temporal pretopology for the analysis for structural changes. Application to econometrics ». International Journal of Data Warehousing and Mining (IJDWM). doi : 10.4018/IJDWM.298004. HAL : hal-03565465.
DenisVigier, LudovicMoncla, IsabelleLefort, ThierryJoliveau & KatherineMcdonough (2022). « Les articles de géographie dans le Dictionnaire Universel de Trévoux et l’Encyclopédie de Diderot et d’Alembert ». Langue française. doi : 10.3917/lf.214.0059. HAL : hal-03694141. .
Seif-EddineBenkabou, KhalidBenabdeslem, VivienKraus, KilianBourhis & BrunoCanitia (2022). « Local Anomaly Detection for Multivariate Time Series by Temporal Dependency Based on Poisson Model ». IEEE Transactions on Neural Networks and Learning Systems, vol.33, n°11, pp.6701-6711. doi : 10.1109/TNNLS.2021.3083183. HAL : hal-03955108.
SimonPageaud, AnneEyraud-Loisel, Jean-PierreBertoglio, AlexisBienvenüe, NicolasLeboisne, CatherinePothier, ChristopheRigotti, NicolasPonthus, RomainGauchonet al. (2022). « Predicted Impacts of Booster, Immunity Decline, Vaccination Strategies, and Non-Pharmaceutical Interventions on COVID-19 Outcomes in France ». Vaccines, vol.10, n°12, p.2033. doi : 10.3390/vaccines10122033. HAL : hal-03883673. .
SalvatoreCitraro, LetiziaMilli, RémyCazabet & GiulioRossetti (2022). « $$\Delta $$-Conformity: multi-scale node assortativity in feature-rich stream graphs ». International Journal of Data Science and Analytics. doi : 10.1007/s41060-022-00375-4. ArXiv : 2111.15534. HAL : hal-03874703.
TimothéeChane-Haï, SamuelVercraene, CélineRobardet & ThibaudMonteiro (2022). « Guidage des métaheuristiques par machine-learning, application au transport d'enfants en situation de handicap ». 23ème congrès annuel de la Société Française de Recherche Opérationnelle et d'Aide à la Décision, 25 février 2022, Villeurbanne - Lyon (France).HAL : hal-03595296. .
LudovicMoncla, KhaledChabane & AliceBrenon (2022). « Classification automatique d'articles encyclopédiques ». Extraction et Gestion des Connaissances (EGC'2022), 25 janvier 2022, Blois (France).HAL : hal-03481219. .
JorgeRamírez, MarcosBaez, AudayBerro, BoualemBenatallah & FabioCasati (2022). « Crowdsourcing Syntactically Diverse Paraphrases with Diversity-Aware Prompts and Workflows ». International Conference on Advanced Information Systems Engineering, 10 juin 2022, Leuven (Belgique), pp.253-269. doi : 10.1007/978-3-031-07472-1_15. HAL : hal-04510766. .
YacineGaci, BoualemBenatallah, FabioCasati & KhalidBenabdeslem (2022). « Iterative Adversarial Removal of Gender Bias in Pretrained Word Embeddings ». The 37th ACM/SIGAPP Symposium on Applied Computing (SAC ’22), 25 avril 2022, Prague (virtual) (République Tchèque), pp.829-836. doi : 10.1145/3477314.3507274. HAL : hal-03626768. .
YacineGaci, BoualemBenatallah, FabioCasati & KhalidBenabdeslem (2022). « Masked Language Models as Stereotype Detectors? ». EDBT 2022, 29 mars 2022, Edinburgh (Royaume-Uni).HAL : hal-03626753. .
NatkamonTovanich & RémyCazabet (2022). « Pattern Analysis of Money Flow in the Bitcoin Blockchain ». The 11th International Conference on Complex Networks and their Applications, 10 novembre 2022, Palermo (Italie), pp.443-455. doi : 10.1007/978-3-031-21127-0_36. ArXiv : 2207.07315. HAL : hal-03896866. .
YacineGaci, BoualemBenatallah, FabioCasati & KhalidBenabdeslem (2022). « Conceptual Similarity for Subjective Tags ». AACL-IJCNLP 2022 (2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing), 20 novembre 2022, Online (Taïwan).HAL : hal-03866253. .
YassineHmidy, AgnèsRico & OlivierStrauss (2022). « Extending the Macsum Aggregation to Interval-Valued Inputs ». SUM 2022 - 15th International Conference Scalable Uncertainty Management, 19 octobre 2022, Paris (France), pp.338-347. doi : 10.1007/978-3-031-18843-5_23. HAL : hal-03927383. .
YacineGaci, BoualemBenattallah, FabioCasati & KhalidBenabdeslem (2022). « Debiasing Pretrained Text Encoders by Paying Attention to Paying Attention ». 2022 Conference on Empirical Methods in Natural Language Processing, 11 décembre 2022, Abu Dhabi (Émirats Arabes Unis), pp.9582-9602. HAL : hal-03919992. .
MehdiHennequin, KhalidBenabdeslem & HaythamElghazel (2022). « Adversarial Multi - View Domain Adaptation for Regression ». 2022 International Joint Conference on Neural Networks (IJCNN), 23 juillet 2022, Padua (Italie), pp.1-8. doi : 10.1109/IJCNN55064.2022.9892148. HAL : hal-03898518.
KhoulaMeddahi, Seif-EddineBenkabou, AllelHadjali, AminMesmoudi, DouEl Kefel Mansouri, KhalidBenabdeslem & SouleymanChaib (2022). « Towards a Co-selection Approach for a Global Explainability of Black Box Machine Learning Models ». International Conference on Web Information Systems Engineering, 3 novembre 2022, Biarrritz (France), pp.97-109. doi : 10.1007/978-3-031-20891-1_8. HAL : hal-03955123.
MehdiHennequin, KhalidBenabdeslem & HaythamElghazel (2022). « Adversarial Multi-View Domain Adaptation for Regression ». 2022 International Joint Conference on Neural Networks (IJCNN), 23 juillet 2022, Padoue (Italie).doi : 10.1109/IJCNN55064.2022.9892148. HAL : hal-04382606. .
MehdiHennequin, KhalidBenabdeslem, HaythamElghazel, ThomasRanvier & EricMichoux (2022). « Multi-View Self-Attention for Regression Domain Adaptation with Feature Selection ». 29th International Conference on Neural Information Processing, 26 novembre 2022, New Delhi (Inde), pp.177-188. doi : 10.1007/978-3-031-30105-6_15. HAL : hal-04230643. .
RafaelRamos Tubino, RémyCazabet & CélineRobardet (2022). « Vers une meilleure identification d'acteurs de Bitcoin par apprentissage supervisé ». Conférence francophone sur l'Extraction et la Gestion des Connaissances (EGC 2022), 28 janvier 2022, Blois (France), pp.171-182. HAL : hal-04193274. .
SaraBouguelia, AudayBerro, BoualemBenatallah, MarcosBáez, HayetBrabra, ShayanZamanirad & HamamacheKheddouci (2022). « Process-oriented intents: a cornerstone for superimposition of natural language conversations over composite services ». The 20th International Conference on Service-Oriented Computing (ICSOC), 2 décembre 2022, Seville (Espagne), pp.575-583. doi : 10.1007/978-3-031-20984-0_41. HAL : hal-03990939. .
MiguelPalencia-Olivar, StephaneBonnevay, AlexandreAussem & BrunoCanitia (2022). « Nonparametric neural topic modeling for customer insight extraction about the tire industry ». 2022 International Joint Conference on Neural Networks (IJCNN), 23 juillet 2022, Padua (Italie), pp.01-09. doi : 10.1109/IJCNN55064.2022.9892577. HAL : hal-03898500.
SébastienDestercke, AgnèsRico & OlivierStrauss (2022). « Using atomic bounds to get sub-modular approximations ». 15th International Conference Scalable Uncertainty Management (SUM 2022), 19 octobre 2022, Paris (France), pp.64-78. doi : 10.1007/978-3-031-18843-5_5. HAL : hal-03895923. .
NatkamonTovanich & RémyCazabet (2022). « Pattern Analysis of Money Flows in the Bitcoin Blockchain ». NetSci 2022: International School and Conference on Network Science, 29 juillet 2022, Shanghai (Chine).HAL : hal-03898095.
FlorenceGondret, MasoomehTaghipoor, AurélienMadouasse, AlexandreTermier, ClaireVerplanck, CélineRobardet, RomainPiovan & EdouardAsselin (2022). « WAIT4: un projet collaboratif sur l'évaluation en dynamique du bien-être des animaux d'élevage - de la captation de la donnée à la découverte de motifs signifiants et de seuils d'alertes spécifiques ». Annual meeting - Metaprogram DIGIT-BIO Biologie numérique pour explorer et prédire le vivant, 9 décembre 2022, Ecully (France).HAL : hal-04337044. .
SimonScheider, LudovicMoncla & GabrielViehhauser (2022). « Discovering Spatial Referencing Strategies in Environmental Narratives ». Unlocking Environmental Narratives: Towards Understanding Human Environment Interactions through Computational Text Analysis, Ubiquity Press, pp.211-232. doi : 10.5334/bcs.k. HAL : hal-03899551. .
Katrín AnnaLund, LudovicMoncla & GabrielViehhauser (2022). « Glacial Narratives: How Can They Be Captured? ». Unlocking Environmental Narratives: Towards Understanding Human Environment Interactions through Computational Text Analysis, Ubiquity Press, pp.93-108. doi : 10.5334/bcs.e. HAL : hal-03899546. .
PénélopeDuval, EMartin, LVallon, ASignoret, PAntonelli, PLuis, GMinard, LaureWiest, AurélieFildieret al. (2022). « Interplay between social and environmental risk factors and consequences on the development of the Asian tiger mosquito in urban areas ». 10. Congress of the International Symbiosis Society, 25 juillet 2022, Lyon (France). Poster. HAL : hal-03815960.
JorgeRamírez, AudayBerro, MarcosBaez, BoualemBenatallah & FabioCasati (2022). « Crowdsourcing Diverse Paraphrases for Training Task-oriented Bots ». ArXiv : 2109.09420. HAL : hal-03626692. .
AudayBerro, Mohammad-Ali Yaghub ZadeFard, MarcosBaez, BoualemBenatallah & KhalidBenabdeslem (2021). « An extensible and reusable pipeline for automated utterance paraphrases ». Proceedings of the VLDB Endowment (PVLDB), vol.14, n°12, pp.2839-2842. doi : 10.14778/3476311.3476358. HAL : hal-04451718.
AbdelouahidAlalga, KhalidBenabdeslem & Dou El KefelMansouri (2021). « 3-3FS: ensemble method for semi-supervised multi-label feature selection ». Knowledge and Information Systems (KAIS), vol.63, n°11, pp.2969-2999. doi : 10.1007/s10115-021-01616-x. HAL : hal-04451721.
AudayBerro, MarcosBaez, BoualemBenatallah, KhalidBenabdeslem & Mohammad-Ali Yaghub ZadeFard (2021). « Automated Paraphrase Generation with Over-generation and Pruning Services ». Lecture Notes in Computer Science, vol.13121, pp.400-414. doi : 10.1007/978-3-030-91431-8_25. HAL : hal-03626684. .
JacquesFize, LudovicMoncla & BrunoMartins (2021). « Deep Learning for Toponym Resolution: Geocoding Based on Pairs of Toponyms ». ISPRS International Journal of Geo-Information, vol.10, n°12, p.818. doi : 10.3390/ijgi10120818. HAL : hal-03464000. .
Dou El KefelMansouri, BachirKaddar, Seif-EddineBenkabou & KhalidBenabdeslem (2021). « The Mode-Fisher pooling for time complexity optimization in deep convolutional neural networks ». Neural Computing and Applications, vol.33, n°12, pp.6443-6465. doi : 10.1007/s00521-020-05406-4. HAL : hal-03937288.
SimonPageaud, CatherinePothier, ChristopheRigotti, AnneEyraud-Loisel, Jean-PierreBertoglio, AlexisBienvenüe, NicolasLeboisne, NicolasPonthus, RomainGauchonet al. (2021). « Expected Evolution of COVID-19 Epidemic in France for Several Combinations of Vaccination Strategies and Barrier Measures ». Vaccines, vol.9, n°12, p.1462. doi : 10.3390/vaccines9121462. HAL : hal-03482342. .
M.Moranges, C.Rouby, MarcPlantevit & M.Bensafi (2021). « Explicit and implicit measures of emotions: Data-science might help to account for data complexity and heterogeneity ». Food Quality and Preference, vol.92, p.104181. doi : 10.1016/j.foodqual.2021.104181. ArXiv : 2205.01939. HAL : hal-03658160. .
Conférences (20)
Conférences internationales avec comité de lecture (16)
AliceBrenon & DenisVigier (2021). « The specificities of encoding encyclopedias: towards a new standard? ». ICHLL11: 11th International Conference on Historical Lexicography and Lexicology, 16 juin 2021, Logroño, Universidad de La Rioja (Espagne).HAL : halshs-03266745.
YoucefRemil, AnesBendimerad, MarcPlantevit, CélineRobardet & MehdiKaytoue (2021). « Interpretable Summaries of Black Box Incident Triaging with Subgroup Discovery ». 8th IEEE International Conference on Data Science and Advanced Analytics (DSAA 2021), 9 octobre 2021, Porto (Portugal).doi : 10.1109/DSAA53316.2021.9564164. ArXiv : 2108.03013. HAL : hal-03318094. .
AudayBerro, Mohammad-AliYaghub Zade Fard, MarcosBaez, BoualemBenatallah & KhalidBenabdeslem (2021). « An Extensible and Reusable Pipeline for Automated Utterance Paraphrases ». 47th International Conference on Very Large Data Bases, 20 août 2021, Copenhagen (Danemark).doi : 10.14778/3476311.3476358. HAL : hal-03399085. .
ThomasRanvier, KilianBourhis, KhalidBenabdeslem & BrunoCanitia (2021). « Deep Multi-View Learning for Tire Recommendation ». 2021 International Joint Conference on Neural Networks (IJCNN), 22 juillet 2021, Shenzhen (Chine), pp.1-8. doi : 10.1109/IJCNN52387.2021.9534318. ArXiv : 2203.12451. HAL : hal-03614780. .
RémiVaudaine, ChristineLargeron & RémyCazabet (2021). « Comparaison de la capacité des plongements de graphes à capturer les propriétés des réseaux ». Conférence Extraction et gestion des connaissances EGC 2021, Montpellier (France).HAL : hal-03471459.
AlessandroChiappori & RémyCazabet (2021). « Quantitative Evaluation of Snapshot Graphs for the Analysis of Temporal Networks ». COMPLEX NETWORKS 2021 - 10th International Conference on Complex Networks and their Applications, 2 décembre 2021, Madrid (Espagne).HAL : hal-03560917. .
YacineGaci, JorgeRamírez, BoualemBenatallah, FabioCasati & KhalidBenabdslem (2021). « Subjectivity Aware Conversational Search Services ». 24th International Conference on Extending Database Technology (EDBT 2021), 23 mars 2021, Nicosia (on line) (Chypre).doi : 10.5441/002/edbt.2021.15. HAL : hal-03296927. .
YoucefRemil (2021). « How Can Subgroup Discovery Help AIOps? ». 36th IEEE/ACM International Conference on Automated Software Engineering (ASE 2021), 19 novembre 2021, Melbourne (Australie), pp.1098-1100. doi : 10.1109/ASE51524.2021.9678697. ArXiv : 2109.04909. HAL : hal-03627826. .
YoucefRemil, AnesBendimerad, RomainMathonat, PhilippeChaleat & MehdiKaytoue (2021). « What makes my queries slow?": Subgroup Discovery for SQL Workload Analysis" ». 36th IEEE/ACM International Conference on Automated Software Engineering, ASE 2021, 19 novembre 2021, Melbourne (Australie), pp.642-652. doi : 10.1109/ASE51524.2021.9678915. ArXiv : 2108.03906. HAL : hal-03318172. .
LudovicMoncla, DenisVigier, KatherineMcdonough, AliceBrenon & ThierryJoliveau (2021). « Combinaison d’approches qualitative et quantitative pour le repérage et la classification des entités nommées dans l’Encyclopédie de Diderot et d’Alembert (1751-1772) ». Theoretical linguistics in the light of the interaction of qualitative and quantitative approaches, 21 juin 2021, Neuchâtel (Suisse).HAL : halshs-03271672.
TimothéeChane-Haï, SamuelVercraene, CélineRobardet & ThibaudMonteiro (2021). « Knowledge-guided search applied to the transportation of disabled people ». Smart Healthcare International Conference - SHeIC 2021, 3 décembre 2021, Troyes (France) (France).HAL : hal-04398625. .
ThomasRanvier, KhalidBenabdeslem, KilianBourhis & BrunoCanitia (2021). « Apprentissage multi-vues pour la recommandation dans le domaine du pneumatique ». Extraction et Gestion des Connaissances (EGC) 2021, 29 janvier 2021, Montpellier (France), pp.261-268. HAL : hal-04230586. .
MohamedBenabdelkrim, CélineRobardet & JeanSavinien (2021). « Leveraging semantic for community mining in multilayer networks ». Canadian AI, 25 mai 2021, Vancouver (Canada).HAL : hal-03340780. .
Conférences nationales avec comité de lecture (2)
NadiaBennani, SylvieCazalens, VincentCheutet, ClaireLeschi, OdysséeMerveille, CamilleMoriot, DelphineMuller, TimothéePecatte, CatherinePothieret al. (2021). « Apprivoiser l'hétérogénéité en informatique 1ère année ». COLLOQINSA 2021 - 7e Colloque pédagogie et formation, 21 mai 2021, Valenciennes (France), pp.1-6. HAL : hal-03230531. .
NoëlieDebs, SergioPeignier, ClémentDouarre, ThéoJourdan, ChristopheRigotti & CaroleFrindel (2021). « Apprendre l'apprentissage automatique : un retour d'expérience ». CETSIS 2021 - Colloque de l'Enseignement des Technologies et des Sciences de l'Information et des Systèmes, 10 juin 2021, Valenciennes (France), pp.1-5. HAL : hal-03341954. .
Autres conférences (2)
LudovicMoncla, DenisVigier, KatherineMcdonough, AliceBrenon & ThierryJoliveau (2021). « Approche symbolique pour la classification des entités nommées dans l'Encyclopédie de Diderot et d'Alembert ». Atelier UChicago Center "Données et discours géographiques en France au 18e siècle", 14 juin 2021, Paris (France).HAL : hal-03259058.
LudovicMoncla, KhaledChabane & AliceBrenon (2021). « Domaines et articles dans l'Encyclopédie : problèmes de classification ». Atelier UChicago Center "Données et discours géographiques en France au 18e siècle", 15 juin 2021, Paris (France).HAL : hal-03259053.
HDR, thèses (7)
Thèses (7)
LouisDuvivier (2021). « Two statistical methods for graph model selection : Distance to the microcanonical ensemble and prequential inference on edge sequences ». HAL : tel-03670853. .
ClémentSage (2021). « Deep learning for information extraction from business documents ». HAL : tel-03521607. .
AlexandreMillot (2021). « Exceptional model mining meets multi-objective optimization : Application to plant growth recipes in controlled environments ». HAL : tel-03625305. .
MohamedBenabdelkrim (2021). « Les communautés dans les multigraphes de co-appartenance : Application aux listes Twitter ». HAL : tel-03670875. .
VivienKraus (2021). « Apprentissage semi-supervisé pour la régression multi-labels : application à l’annotation automatique de pneumatiques ». HAL : tel-03789608. .
AlexandreMillot (2021). « Exceptional Model Mining meets Multi-Objective Optimization: Application to Plant Growth Recipes in Controlled Environments ». HAL : tel-03390102. .
Rapports (2)
Rapports de recherche/technique (2)
SimonPageaud, NicolasPonthus, RomainGauchon, CatherinePothier, ChristopheRigotti, AnneEyraud-Loisel, Jean-PierreBertoglio, AlexisBienvenüe, FrançoisGueyffieret al. (2021). « Adapting French COVID-19 vaccination campaign duration to variant dissemination ». Rapport de recherche. p.24. HAL : hal-03294952. .
RomainGauchon, NicolasPonthus, CatherinePothier, ChristopheRigotti, VitalyVolpert, StéphaneDerrode, Jean-PierreBertoglio, AlexisBienvenüe, Pierre-OlivierGoffardet al. (2021). « Lessons learnt from the use of compartmental models over the COVID-19 induced lockdown in France ». Rapport de recherche. p.39. HAL : hal-03341704. .
Autres (4)
JacquesFize, LudovicMoncla & BrunoMartins (2021). « Résolution de toponymes par apprentissage profond à partir de cooccurrences et de relations spatiales. ». 16th Spatial Analysis and Geomatics Conference (SAGEO 2021), 5 mai 2021, La Rochelle (France). Poster. HAL : hal-03225106. .
JacquesFize, LucileSautot, MartinLentschat, LudovicJournaux & MohamedHilal (2021). « Contributeurs au Grand Débat National demandant un développement du réseau ferroviaire et/ou une augmentation de la fréquence des trains dans l'Hérault ». HAL : hal-03375400. .
JacquesFize, LucileSautot, MartinLentschat, LudovicJournaux & MohamedHilal (2021). « Contributeurs au Grand Débat National demandant un développement des pistes cyclables dans l'Hérault ». HAL : hal-03375373. .
FrédéricFlouvat, NazhaSelmaoui-Folcher, JérémySanhes, ChengchengMu, ClaudePasquier & Jean-FrançoisBoulicaut (2020). « Mining evolutions of complex spatial objects using a single-attributed Directed Acyclic Graph ». Knowledge and Information Systems (KAIS), vol.62, n°10, pp.3931-3971. doi : 10.1007/s10115-020-01478-9. HAL : hal-02909702. .
RémyCazabet, SouâadBoudebza & GiulioRossetti (2020). « Evaluating Community Detection Algorithms for Progressively Evolving Graphs ». Journal of Complex Networks. doi : 10.1093/comnet/cnaa027. HAL : hal-03173685. .
Conférences (16)
Conférences internationales avec comité de lecture (15)
DihiaBoulegane, AlbertBifet, HaythamElghazel & GiyyarpuramMadhusudan (2020). « Streaming Time Series Forecasting using Multi-Target Regression with Dynamic Ensemble Selection ». 2020 IEEE International Conference on Big Data (IEEE BigData 2020), Atlanta, GA, USA, December 10-13, 2020, 13 décembre 2020, Atlanta (États-Unis), pp.2170-2179. doi : 10.1109/BIGDATA50022.2020.9378264. HAL : hal-04468437.
CorentinLonjarret, CélineRobardet, MarcPlantevit, RochAuburtin & MartinAtzmueller (2020). « Why Should I Trust This Item? Explaining the Recommendations of any Model ». IEEE International Conference on Data Science and Advanced Analytics (DSAA), 9 octobre 2020, Sydney (Australie).doi : 10.1109/DSAA49011.2020.00067. HAL : hal-02965196.
MohamedBenabdelkrim, JeanSavinien & CélineRobardet (2020). « Finding interest groups from Twitter lists ». SAC '20: The 35th ACM/SIGAPP Symposium on Applied Computing, 30 mars 2020, Brno Czech Republic (France), pp.1885-1887. doi : 10.1145/3341105.3374077. HAL : hal-03340772. .
RémiVaudaine, ChristineLargeron & RémyCazabet (2020). « Comparing the preservation of network properties by graph embeddings ». Eighteenth International Symposium on Intelligent Data Analysis (IDA 2020), 27 avril 2020, Bodenseeforum (Allemagne).doi : 10.1007/978-3-030-44584-3_41. HAL : hal-02456857.
AnesBendimerad, JefreyLijffijt, MarcPlantevit, CélineRobardet & TijlDe Bie (2020). « Gibbs Sampling Subjectively Interesting Tiles ». Advances in Intelligent Data Analysis {XVIII} - 18th International Symposium on Intelligent Data Analysis (IDA 2020), Konstanz (on line) (Allemagne).doi : 10.1007/978-3-030-44584-3_7. HAL : hal-02960847. .
RémyCazabet (2020). « Data Compression to Choose a Proper Dynamic Network Representation ». International Conference on Complex Networks and Their Applications, Madrid (Espagne), pp.522-532. doi : 10.1007/978-3-030-65347-7_43. HAL : hal-03173720.
WissameLaddada, FabienDuchateau, FranckFavetta & LudovicMoncla (2020). « Ontology-Based Approach for Neighborhood and Real Estate Recommendations ». 4th ACM SIGSPATIAL Workshop on Location-Based Recommendations, Geosocial Networks, and Geoadvertising (LocalRec'20), 6 novembre 2020, Seattle, WA (États-Unis), pp.1-10. doi : 10.1145/3423334.3431452. HAL : hal-03040142. .
FabioMensi, RémyCazabet & AngeloFurno (2020). « Traffic speed prediction in the Lyon area using DCRNN ». Marami 2020, Online (France).HAL : hal-04109252. .
Juan GregorioRejas, CatherinePothier, ChristopheRigotti, NicolasMéger, I.Vasquez, O. C.Rotunno, J.Bonatti & H.Barbosa (2020). « Studying Evolution of Hydrothermal Alteration Materials in the Turrialba Volcano through Multispectral and Hyperspectral Images ». International Society for Photogrammetry and Remote Sensing Congress, Nice (France), 6 pages. doi : 10.5194/isprs-archives-XLIII-B2-2020-1259-2020. HAL : hal-03091306.
ClémentSage, AlexAussem, VéroniqueEglin, HaythamElghazel & JérémyEspinas (2020). « End-to-End Extraction of Structured Information from Business Documents with Pointer-Generator Networks ». EMNLP 2020 Workshop on Structured Prediction for NLP, 20 novembre 2020, Punta Cana (online) (République Dominicaine).HAL : hal-02958913. .
AlexandreMillot, RémyCazabet & Jean-FrançoisBoulicaut (2020). « Découverte d'un sous-groupe optimal dans des données purement numériques ». Extraction et Gestion des Connaissances (EGC), 27 janvier 2020, Bruxelles (Belgique), 25-36.HAL : hal-02483329. .
HDR, thèses (6)
HDR (1)
MehdiKaytoue (2020). « Contributions to Pattern Discovery and Formal Concept Analysis ». HAL : tel-02495263. .
Thèses (5)
LucasFoulon (2020). « Détection d'anomalies dans les flux de données par structure d'indexation et approximation : Application à l'analyse en continu des flux de messages du système d'information de la SNCF ». HAL : tel-03125747. .
RomainMathonat (2020). « Rule discovery in labeled sequential data : Application to game analytics ». HAL : tel-03127321. .
Mohamed AliHammal (2020). « Contribution à la découverte de sous-groupes corrélés : Application à l’analyse des systèmes territoriaux et des réseaux alimentaires ». HAL : tel-03078791. .
RomainMathonat (2020). « Rule Discovery in Labeled Sequential Data: Application to Game Analytics ». HAL : tel-02970006. .
LucasFoulon (2020). « Détection d'anomalies dans les flux de données par structure d'indexation et approximation. Application à l'analyse en continu des flux de messages du système d'information de la SNCF ». HAL : tel-03089142. .
LudovicMoncla, PatriciaMurrieta-Flores & CarmenBrando (2020). « Proceedings of the 4th ACM SIGSPATIAL Workshop on Geospatial Humanities ». HAL : hal-03160455.
SébastienFerré, MarianneHuchard, MehdiKaytoue, SergeiKuznetsov & AmedeoNapoli (2020). « Formal Concept Analysis: From Knowledge Discovery to Knowledge Processing ». A Guided Tour of Artificial Intelligence Research, Pierre Marquis, Odile Papini, Henri Prade, Springer International Publishing, pp.411-445. doi : 10.1007/978-3-030-06167-8_13. HAL : hal-03085699.
DenisVigier, LudovicMoncla, AliceBrenon, KatherineMcdonough & ThierryJoliveau (2020). « Classification des entités nommées dans l'Encyclopédie ou dictionnaire raisonné des sciences des arts et des métiers par une société de gens de lettres (1751-1772) ». Actes du 7ème Congrès Mondial de Linguistique Française, Jul 2020, Montpellier, France. doi : 10.1051/shsconf/20207811008. HAL : hal-02578029. .
Rapports (1)
Rapports de recherche/technique (1)
StéphaneDerrode, RomainGauchon, NicolasPonthus, ChristopheRigotti, CatherinePothier, VitalyVolpert, StéphaneLoisel, Jean-PierreBertoglio & PascalRoy (2020). « Piecewise estimation of R0 by a simple SEIR model. Application to COVID-19 in French regions and departments until June 30, 2020 ». Rapport de recherche. HAL : hal-02910202. .
Autres (4)
LucileSautot, JacquesFize, MartinLentschat & LudovicJournaux (2020). « Contributeurs au Grand Débat National demandant un développement des pistes cyclables dans l'aire urbaine de Grenoble ». HAL : hal-03375443. .
LucileSautot, JacquesFize, MartinLentschat & LudovicJournaux (2020). « Contributeurs au Grand Débat National demandant un développement des pistes cyclables dans l'aire urbaine de Dijon ». HAL : hal-03375432. .
LucileSautot, JacquesFize, MartinLentschat & LudovicJournaux (2020). « Contributeurs au Grand Débat National demandant un développement du réseau ferroviaire et/ou une augmentation de la fréquence des trains dans l'aire urbaine de Dijon ». HAL : hal-03375423. .
LucileSautot, JacquesFize, MartinLentschat & LudovicJournaux (2020). « Contributeurs au Grand Débat National demandant un développement du réseau ferroviaire et/ou une augmentation de la fréquence des trains dans l'aire urbaine de Grenoble. ». HAL : hal-03375450. .
2019 (44)
Revues (8)
Revues internationales avec comité de lecture (8)
NicolasMéger, ChristopheRigotti, CatherinePothier, TuanNguyen, FelicityLodge, LionelGueguen, RémiAndréoli, Marie-PierreDoin & MihaiDatcu (2019). « Ranking evolution maps for Satellite Image Time Series exploration: application to crustal deformation and environmental monitoring ». Data Mining and Knowledge Discovery, vol.33, n°1, pp.131-167. doi : 10.1007/s10618-018-0591-9. HAL : hal-01898015. .
CarmenLicón, GuillaumeBosc, MohammedSabri, MarylouMantel, ArnaudFournel, CarolineBushdid, JérômeGolebiowski, CélineRobardet, MarcPlantevitet al. (2019). « Chemical features mining provides new descriptive structure-odor relationships ». PLoS Computational Biology, vol.15, n°4, e1006945. doi : 10.1371/journal.pcbi.1006945. HAL : hal-02343686.
ArnaudBellec, BernardGauthiez, SergeFenet & BernardKaufmann (2019). « Webarmature : Observatoire diachronique du territoire lyonnais ». Cybergeo : Revue européenne de géographie / European journal of geography. doi : 10.4000/cybergeo.32652. HAL : hal-02458176.
GiulioRossetti, LetiziaMilli & RémyCazabet (2019). « CDLIB: a python library to extract, compare and evaluate communities from complex networks ». Applied Network Science, vol.4, p.52. doi : 10.1007/s41109-019-0165-9. HAL : hal-02197272. .
LudovicMoncla, MauroGaio, ThierryJoliveau, Yves-FrançoisLe Lay, NoémieBoeglin & Pierre-OlivierMazagol (2019). « Mapping urban fingerprints of odonyms automatically extracted from French novels ». International Journal of Geographical Information Science, vol.33, n°12, pp.2477-2497. doi : 10.1080/13658816.2019.1584804. HAL : hal-02070456. .
KatherineMcdonough, LudovicMoncla & MatjeVan De Camp (2019). « Named entity recognition goes to old regime France: geographic text analysis for early modern French corpora ». International Journal of Geographical Information Science, pp.1-25. doi : 10.1080/13658816.2019.1620235. HAL : hal-02141257.
MauroGaio & LudovicMoncla (2019). « Geoparsing and geocoding places in a dynamic space context: The case of hiking descriptions ». Human Cognitive Processing, vol.66, pp.354-386. doi : 10.1075/hcp.66.10gai. HAL : hal-02117833.
Conférences (21)
Conférences internationales avec comité de lecture (18)
Mohamed-AliHammal, BernardoAbreu, MarcPlantevit & CélineRobardet (2019). « Sampling Rank Correlated Subgroups ». Distributed Computing and Artificial Intelligence, 16th International Conference, 28 juin 2019, Avila, Espagne (Espagne), pp.217-225. doi : 10.1007/978-3-030-23887-2_25. HAL : hal-04076705.
Dou El KefelMansouri, Seif-EddineBenkabou, BachirKaddar & KhalidBenabdeslem (2019). « A Novel Proposed Pooling for Convolutional Neural Network ». 2019 IEEE 31st International Conference on Tools with Artificial Intelligence (ICTAI), 6 novembre 2019, Portland (États-Unis), pp.1739-1743. doi : 10.1109/ICTAI.2019.00258. HAL : hal-03961996.
NyomanJuniarta, VictorCodocedo, MiguelCouceiro, MehdiKaytoue & AmedeoNapoli (2019). « Pattern Structures for Identifying Biclusters with Coherent Sign Changes ». ICFCA 2019 - 15th International Conference on Formal Concept Analysis, 28 juin 2019, Frankfurt (Allemagne), pp.1-13. HAL : hal-02166713. .
LucasFoulon, SergeFenet, ChristopheRigotti & DenisJouvin (2019). « Scoring Message Stream Anomalies in Railway Communication Systems ». LMID 2019 - IEEE Workshop on Learning and Mining with Industrial Data, 11 novembre 2019, Beijing (Chine), pp.1-8. doi : 10.1109/ICDMW.2019.00114. HAL : hal-02357924. .
TuanNguyen, NicolasMéger, ChristopheRigotti, CatherinePothier, NoelGourmelen & EmmanuelTrouvé (2019). « A pattern-based mining system for exploring Displacement Field Time Series ». 19th IEEE International Conference on Data Mining (ICDM) Demo, 11 novembre 2019, Beijing (Chine), pp.1110-1113. doi : 10.1109/ICDMW.2019.00165. HAL : hal-02361793. .
LudovicMoncla, KatherineMcdonough, DenisVigier, ThierryJoliveau & AliceBrenon (2019). « Toponym disambiguation in historical documents using network analysis of qualitative relationships ». 3rd ACM SIGSPATIAL International Workshop on Geospatial Humanities, 5 novembre 2019, Chicago (États-Unis), pp.1-4. doi : 10.1145/3356991.3365471. HAL : hal-02350193.
DenisVigier, LudovicMoncla, ThierryJoliveau, KatherineMcdonough & AliceBrenon (2019). « GeoDISCO: Encyclopedic Geographical Discourse in France from the Enlightenment to Wikipedia ». GIR'19, 13th International Workshop on Geographic Information Retrieval, 28 novembre 2019, Lyon (France).HAL : hal-02474835.
LouisDuvivier, CélineRobardet & RémyCazabet (2019). « Minimum entropy stochastic block models neglect edge distribution heterogeneity ». 8th International Conference on Complex Networks and Their Applications (COMPLEX NETWORKS 2019), 12 décembre 2019, Lisbonne (Portugal), pp.545-555. doi : 10.1007/978-3-030-36687-2_45. ArXiv : 1910.07879. HAL : hal-03339803. .
SouâadBoudebza, RémyCazabet, OmarNouali & FaiçalAzouaou (2019). « Detecting Stable Communities in Link Streams at Multiple Temporal Scales ». LEG@ECML-PKDD 2019 - Third International Workshop on Advances in Managing and Mining Large Evolving Graphs, 20 septembre 2019, Wurzburg (Allemagne).doi : 10.1007/978-3-030-43823-4_30. HAL : hal-03261697. .
CorentinLonjarret, MarcPlantevit, CélineRobardet & RochAuburtin (2019). « Recommandation séquentielle à base de séquences fréquentes ». Extraction et Gestion des Connaissances (EGC), 21 janvier 2019, Metz (France).HAL : hal-02914391. .
LoïcBonneval, FabienDuchateau, FranckFavetta, AurélienGentil, MohamedJelassi, MaryvonneMiquel & LudovicMoncla (2019). « Étude des quartiers : défis et pistes de recherche ». Conférence Extraction et Gestion de Connaissances 2019 (EGC2019) Atelier DigitAl Humanities and cuLtural herItAge: data and knowledge management and analysis (DAHLIA 2019) -, 22 janvier 2019, Metz (France).HAL : hal-02005923. .
VictorCodocedo, JaumeBaixeries, MehdiKaytoue & AmedeoNapoli (2019). « Sampling Representation Contexts with Attribute Exploration ». ICFCA 2019 - 15th International Conference on Formal Concept Analysis, 28 juin 2019, Frankfurt (Allemagne), pp.307-314. doi : 10.1007/978-3-030-21462-3_20. HAL : hal-02195498. .
Conférences nationales avec comité de lecture (3)
RomainMathonat, Jean-FrançoisBoulicaut & MehdiKaytoue (2019). « Découverte de sous-groupes à partir de données séquentielles par échantillonnage et optimisation locale ». Extraction et Gestion des Connaissances, 25 janvier 2019, Metz (France), pp.153-164. HAL : hal-02278857. .
LucasFoulon, ChristopheRigotti, SergeFenet & DenisJouvin (2019). « Approximation du score CFOF de détection d’anomalie dans un arbre d’indexation iSAX : Application au contexte SI de la SNCF ». EGC 2019 - 19ème Conférence francophone sur l'Extraction et la Gestion des Connaissances, 25 janvier 2019, Metz (France), pp.1-12. HAL : hal-02019035. .
CharlesDe Lacombe, AntoineMorel, AdneneBelfodil, FrançoisPortet, CyrilLabbé, SylvieCazalens, MarcPlantevit & PhilippeLamarre (2019). « Analyse de comportements relatifs exceptionnels expliquée par des textes : les votes du parlement européen ». Extraction et Gestion des connaissances (EGC), 25 janvier 2019, Metz (France), pp.437-440. HAL : hal-02009172. .
HDR, thèses (4)
Thèses (4)
JulienSalotti (2019). « Méthodes de sélection de voisinage pour la prévision à court-terme du trafic urbain ». HAL : tel-02900506. .
CélineRobardet, AnnaMonreale, LivioBioglio, CarlosAlzate, ValerioBitetta, IlariaBordino, GuidoCaldarelli, AndreaFerretti, RiccardoGuidottiet al. (2019). « ECML PKDD 2018 Workshops - MIDAS 2018 and PAP 2018, Dublin, Ireland, September 10-14, 2018, Proceedings ». HAL : hal-02016451.
RonanHamon, PierreBorgnat, PatrickFlandrin & CélineRobardet (2019). « Transformation from Graphs to Signals and Back ». Vertex-Frequency Analysis of Graph Signals, Springer International Publishing, pp.111-139. doi : 10.1007/978-3-030-03574-7_2. HAL : hal-01949745.
LucasFoulon, SergeFenet, ChristopheRigotti & DenisJouvin (2019). « Detecting Anomalies over Message Streams in Railway Communication Systems ». AALTD@ECML/PKDD 2019 - 4th Workshop on Advanced Analytics and Learning on Temporal Data. Poster, 20 septembre 2019, Wurzburg (Allemagne). Poster. HAL : hal-02357927. .
EricChraibi, LucileSautot, JacquesFize, SébastienPeillet, LudovicJournaux & FlavieCernesson (2019). « How contributors feel about the impact of climate change on their daily lives (online contributions to the Great National Debate - Ecological Transition) ». HAL : hal-02935752. .
EricChraibi, LucileSautot, JacquesFize, SébastienPeillet, LudovicJournaux & FlavieCernesson (2019). « Number of online contributions to the Great National Debate -Grand Débat National- (Ecological Transition) in mainland France ». HAL : hal-02935718. .
AnilNarassiguin & SelinaSargent (2019). « Data Science for Influencer Marketing : feature processing and quantitative analysis ». ArXiv : 1906.05911. HAL : hal-02120859. .
2018 (30)
Revues (8)
Revues internationales avec comité de lecture (8)
DenisLecoeuche, AlexAussem & MaximeGasse (2018). « On the use of binary stochastic autoencoders for multi-label classification under the zero-one loss ». Procedia Computer Science, vol.144, pp.71-80. doi : 10.1016/j.procs.2018.10.506. HAL : hal-02042711.
SouâadBoudebza, RémyCazabet, FaiçalAzouaou & OmarNouali (2018). « OLCPM: An Online Framework for Detecting Overlapping Communities in Dynamic Social Networks ». Computer Communications. doi : 10.1016/j.comcom.2018.04.003. ArXiv : 1804.03842. HAL : hal-01761341. .
LudovicMoncla & MauroGaio (2018). « Services Web pour l’annotation sémantique d’information spatiale à partir de corpus textuels ». Revue Internationale de Géomatique, vol.28, n°4, pp.439-459. doi : 10.3166/rig.2018.00066. HAL : hal-02113434. .
TuanNguyen, NicolasMéger, ChristopheRigotti, CatherinePothier, EmmanuelTrouvé, NoelGourmelen & Jean-LouisMugnier (2018). « A pattern-based method for handling confidence measures while mining satellite displacement field time series. Application to Greenland ice sheet and Alpine glaciers ». IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol.11, n°11, pp.4390-4402. doi : 10.1109/JSTARS.2018.2874499. HAL : hal-01912708. .
GiulioRossetti & RémyCazabet (2018). « Community Discovery in Dynamic Networks: a Survey ». ACM Computing Surveys, vol.2, n°51, p.35. doi : 10.1145/3172867. HAL : hal-01658399. .
JaumeBaixeries, VictorCodocedo, MehdiKaytoue & AmedeoNapoli (2018). « Characterizing Approximate-Matching Dependencies in Formal Concept Analysis with Pattern Structures ». Discrete Applied Mathematics, vol.249, pp.18-27. doi : 10.1016/j.dam.2018.03.073. HAL : hal-01673441. .
Conférences (17)
Conférences internationales avec comité de lecture (16)
VivienKraus, KhalidBenabdeslem & FredericCherqui (2018). « Régression Laplacienne semi-supervisée pour la reconstitution des dates de pose des réseaux d'assainissement ». Extraction et gestion des Connaissances (EGC), Paris (France).HAL : hal-01794095.
KatherineMcdonough, LudovicMoncla & MatjeVan De Camp (2018). « Expérimentation de méthodes d’extraction d’informations géographiques pour les documents historiques ». Atelier Humanités Numériques Spatialisées (HumaNS’2018) - SAGEO 2018, 6 novembre 2018, Montpellier (France).HAL : hal-01917024.
MaëlleMoranges, MarcPlantevit, ArnaudFournel, MoustafaBensafi & CélineRobardet (2018). « Exceptional Attributed Subgraph Mining To Understand The Olfactory Percept ». 21st International Conference on Discovery Science, 31 octobre 2018, Limassol (Chypre), pp.276-291. HAL : hal-01878375. .
AnesBendimerad, AhmadMel, JefreyLijffijt, MarcPlantevit, CélineRobardet & TijlDe Bie (2018). « Mining Subjectively Interesting Attributed Subgraphs ». INTERNATIONAL WORKSHOP ON MINING AND LEARNING WITH GRAPHS, held with SIGKDD 2018, 20 août 2018, Londres (Royaume-Uni).HAL : hal-02060190. .
AimeneBelfodil, SergeiKuznetsov & MehdiKaytoue (2018). « Pattern Setups and Their Completions ». The 14th International Conference on Concept Lattices and Their Applications (CLA 2018), 14 juin 2018, Olomouc (République Tchèque), pp.243-253. HAL : hal-01818740. .
LucianoGervasoni, SergeFenet & PeterSturm (2018). « Une méthode pour l’estimation désagrégée de données de population à l’aide de données ouvertes ». EGC 2018 - 18ème Conférence Internationale sur l'Extraction et la Gestion des Connaissances, 26 janvier 2018, Paris (France), pp.83-94. HAL : hal-01667975. .
NyomanJuniarta, VictorCodocedo, MiguelCouceiro & AmedeoNapoli (2018). « Biclustering Based on FCA and Partition Pattern Structures for Recommendation Systems ». NFMCP 2018 - 7th International Workshop on New Frontiers in Mining Complex Patterns, 14 septembre 2018, Dublin (Irlande).HAL : hal-01889384. .
AakashSinha, RémyCazabet & RémiVaudaine (2018). « Systematic Biases in Link Prediction: comparing heuristic and graph embedding based methods ». Complex networks 2018 - The 7th International Conference on Complex Networks and Their Applications, Cambridge (Royaume-Uni).doi : 10.1007/978-3-030-05411-3_7. ArXiv : 1811.12159. HAL : hal-01892997. .
Seif-EddineBenkabou, KhalidBenabdeslem & FredericCherqui (2018). « An improved Laplacian semi-supervised regression ». 30th International Conference on Tools with Artificial Intelligence, 7 novembre 2018, Volos (Grèce).HAL : hal-01954836.
JulienSalotti, SergeFenet, RomainBillot, Nour-EddinFaouzi & ChristineSolnon (2018). « Comparison of traffic forecasting methods in urban and suburban context ». ICTAI 2018 : IEEE 30th International Conference on Tools with Artificial Intelligence, 7 novembre 2018, Volos (Grèce), pp.846-853. doi : 10.1109/ICTAI.2018.00132. HAL : hal-01895136. .
VictorCodocedo, JaumeBaixeries, MehdiKaytoue & AmedeoNapoli (2018). « Characterizing Covers of Functional Dependencies using FCA ». CLA 2018 - The 14th International Conference on Concept Lattices and Their Applications, 14 juin 2018, Olomouc (République Tchèque), pp.279-290. HAL : hal-01856516. .
LucianoGervasoni, SergeFenet, RégisPerrier & PeterSturm (2018). « Convolutional neural networks for disaggregated population mapping using open data ». DSAA 2018 - 5th IEEE International Conference on Data Science and Advanced Analytics, 4 octobre 2018, Turin (Italie), pp.594-603. doi : 10.1109/DSAA.2018.00076. HAL : hal-01852585. .
TuanNguyen, NicolasMéger, ChristopheRigotti, CatherinePothier, EmmanuelTrouvé & Jean-LouisMugnier (2018). « Finding Complementary and Reliable Patterns in Displacement Field Time Series of Alpine Glaciers ». IGARSS 2018 - IEEE International Geoscience and Remote Sensing Symposium, 27 juillet 2018, Valencia (Espagne), pp.4213-4216. HAL : hal-01868749. .
SergioPeignier, ChristopheRigotti, AnthonyRossi & GuillaumeBeslon (2018). « Weight-based search to find clusters around medians in subspaces ». SAC 2018 - ACM Symposium On Applied Computing, 13 avril 2018, Pau (France), pp.1-10. HAL : hal-01869974. .
AimeneBelfodil, AdneneBelfodil & MehdiKaytoue (2018). « Anytime Subgroup Discovery in Numerical Domains with Guarantees ». Machine Learning and Knowledge Discovery in Databases - European Conference, ECML PKDD 2018, 10 septembre 2018, Dublin (Irlande), pp.500-516. doi : 10.1007/978-3-030-10928-8_30. HAL : hal-02117627. .
LudovicMoncla, MauroGaio & ThierryJoliveau (2018). « Cartographier les odonymes de Paris cités dans les romans du XIXème siècle ». Atelier Humanités Numériques Spatialisées (HumaNS’2018) - SAGEO 2018, 6 novembre 2018, Montpellier (France).HAL : hal-01917027.
Conférences nationales avec comité de lecture (1)
NyomanJuniarta, VictorCodocedo, MiguelCouceiro & AmedeoNapoli (2018). « Biclustering Based on FCA and Partition Pattern Structures for Recommendation Systems ». SFC 2018 - XXVèmes Rencontres de la Société Francophone de Classification, 7 septembre 2018, Paris (France).HAL : hal-01889309. .
HDR, thèses (4)
HDR (1)
MarcPlantevit (2018). « Contributions to Pattern Mining in Augmented Graphs ». HAL : tel-01956252. .
Thèses (3)
AnilNarassiguin (2018). « Ensemble Learning, Comparative Analysis and Further Improvements with Dynamic Ensemble Selection ». HAL : tel-02146962. .
TuanNguyen (2018). « Prise en compte de la qualité des données lors de l’extraction et de la sélection d’évolutions dans les séries temporelles de champs de déplacements en imagerie satellitaire ». HAL : tel-01939255. .
Seif-EddineBenkabou (2018). « Détection d’anomalies dans les séries temporelles : application aux masses de données sur les pneumatiques ». HAL : tel-01839074. .
Autres (1)
RomainBillot, SergeFenet, JulienSalotti, Nour EddinEl Faouzi & ChristineSolnon (2018). « Comparaison de méthodes de prévision à court terme du trafic en milieux urbain et périurbain ». CAP 2018 conférence sur l'apprentissage automatique, 20 juin 2018, Rouen (France). Poster. HAL : hal-02505831.
2017 (28)
Revues (5)
Revues internationales avec comité de lecture (5)
WillyUgarte, PatriceBoizumault, BrunoCrémilleux, AlbanLepailleur, SamirLoudni, MarcPlantevit, ChedyRaïssi & ArnaudSoulet (2017). « Skypattern mining: From pattern condensed representations to dynamic constraint satisfaction problems ». Artificial Intelligence, vol.244, pp.48-69. doi : 10.1016/j.artint.2015.04.003. HAL : hal-02048224. .
SergioPeignier, JonasAbernot, ChristopheRigotti & GuillaumeBeslon (2017). « EvoMove: Evolutionary-based living musical companion ». European Conference on Artificial Life (ECAL), 8 septembre 2017, Villeurbanne (France), pp.1-8. HAL : hal-01569091. .
QuentinLabernia, VictorCodocedo, CélineRobardet & MehdiKaytoue (2017). « Mining the Lattice of Binary Classifiers for Identifying Duplicate Labels in Behavioral Data ». 30th International Conference on Industrial Engineering and Other Applications of Applied Intelligent Systems, 30 juin 2017, Arras (France), pp.40-21. doi : 10.1007/978-3-319-60045-1_2. HAL : hal-01551395. .
LucianoGervasoni, MartíBosch, SergeFenet & PeterSturm (2017). « Calculating spatial urban sprawl indices using open data ». 15th International Conference on Computers in Urban Planning and Urban Management, 14 juillet 2017, Adelaide (Australie).HAL : hal-01535469. .
RémyCazabet, RimBaccour & MatthieuLatapy (2017). « Tracking bitcoin users activity using community detection on a network of weak signals ». The 6th International Conference on Complex Networks and Their Applications, 29 novembre 2017, Lyon (France).ArXiv : 1710.08158. HAL : hal-01617992. .
Van-TinhTran & AlexAussem (2017). « Reducing variance due to importance weighting in covariate shift bias correction ». European Symposium on Artificial Neural Networks, Bruges (Belgique).HAL : hal-02042795.
Seif-EddineBenkabou, KhalidBenabdeslem & BrunoCanitia (2017). « L2-Type Regularization-based Unsupervised Anomaly Detection from Temporal Data ». IEEE IJCNN, 14 mai 2017, Alaska (États-Unis).HAL : hal-01458412.
TuanNguyen, NicolasMéger, ChristopheRigotti, CatherinePothier, EmmanuelTrouvé & NoelGourmelen (2017). « Handling coherence measures of displacement field time series: Application to Greenland ice sheet glaciers ». 9th International Workshop on the Analysis of Multitemporal Remote Sensing Images (MultiTemp), 29 septembre 2017, Brugge (Belgique), pp.1-4. doi : 10.1109/Multi-Temp.2017.8035228. HAL : hal-01591461.
AnilNarassiguin, HaythamElghazel & AlexAussem (2017). « Dynamic Ensemble Selection with Probabilistic Classifier Chains ». European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML-PKDD 2017), 18 septembre 2017, Skopje (Macédoine), pp.169-186. HAL : hal-02018695.
Seif-EddineBenkabou, KhalidBenabdeslem & BrunoCanitia (2017). « Local-to-Global unsupervised anomaly detection from temporal data ». PAKDD, 23 mai 2017, Jeju (Corée du Sud).HAL : hal-01458411.
Conférences nationales avec comité de lecture (5)
Seif-EddineBenkabou, KhalidBenabdeslem & BrunoCanitia (2017). « Régularisation Ridge pour la détection non-supervisée à partir de séries temporelles ». SFC: Société Francophone de Classification, 30 juin 2017, Lyon (France).HAL : hal-01581660.
LucianoGervasoni, MartìBosch, SergeFenet & PeterSturm (2017). « LUM_OSM : une plateforme pour l'évaluation de la mixité urbaine à partir de données participatives ». Atelier Gestion et Analyse des données Spatiales et Temporelles, 24 janvier 2017, Grenoble (France), pp.3-23. HAL : hal-01548341. .
LucasRezakhanlou, SergeFenet, LucianoGervasoni & PeterSturm (2017). « USAT (Urban Sprawl Analysis Toolkit) : une plateforme web d'analyse de l'étalement urbain à partir de données massives ouvertes ». Atelier Démo de la conférence SAGEO (Spatial Analysis and Geomatics), 6 novembre 2017, Rouen (France).HAL : hal-01610738. .
ElodieScholastique, CatherinePothier, LouisVinet, ChristopheRigotti & NicoleBouillod (2017). « 3D Geomodelling Contribution to the Mapping of Gravitational Hazards on the Hill of Croix-Rousse ». Journées Aléas Gravitaires (JAG), 25 octobre 2017, Besançon (France), pp.1-4. HAL : hal-01596585. .
GuillaumeBosc, Jean-FrançoisBoulicaut, ChedyRaïssi & MehdiKaytoue (2017). « Découverte de sous-groupes avec les arbres de recherche de Monte Carlo ». Extraction et Gestion de Connaissances EGC 2017, 27 janvier 2017, Grenoble (France).HAL : hal-01433054. .
HDR, thèses (4)
Thèses (4)
MaximeGasse (2017). « Probabilistic Graphical Model Structure Learning : Application to Multi-Label Classification ». HAL : tel-01442613. .
Van-TinhTran (2017). « Selection Bias Correction in Supervised Learning with Importance Weight ». HAL : tel-01661470. .
GuillaumeBosc (2017). « Anytime discovery of a diverse set of patterns with Monte Carlo tree search ». HAL : tel-02001153. .
OuadieGharroudi (2017). « Ensemble multi-label learning in supervised and semi-supervised settings ». HAL : tel-01736344. .
NicolasMéger, EdoardoPasolli, ChristopheRigotti, EmmanuelTrouvé & FaridMelgani (2017). « Satellite Image Time Series: mathematical models for data mining and missing data restoration ». Mathematical Models for Remote Sensing Image Processing, Gabriele Moser, Josiane Zerubia, Springer International Publishing, pp.357-398. doi : 10.1007/978-3-319-66330-2. HAL : hal-01567675.
2016 (40)
Revues (6)
Revues internationales avec comité de lecture (6)
HaythamElghazel, AlexAussem, OuadieGharroudi & WafaSaadaoui (2016). « Ensemble Multi-label Text Categorization based on Rotation Forest and Latent Semantic Indexing ». Expert Systems with Applications, vol.57, pp.1-11. HAL : hal-01375162.
AnilNarassiguin, MohamedBibimoune, HaythamElghazel & AlexAussem (2016). « An Extensive Empirical Comparison of Ensemble Learning Methods for Binary Classification ». Pattern Analysis and Applications, vol.19, n°4, pp.1093-1128. doi : 10.1007/s10044-016-0553-z. HAL : hal-01375159.
RonanHamon, PierreBorgnat, PatrickFlandrin & CélineRobardet (2016). « Extraction of Temporal Network Structures from Graph-based Signals ». IEEE Transactions on Signal and Information Processing over Networks, vol.2, n°2, pp.215-226. doi : 10.1109/TSIPN.2016.2530562. HAL : hal-01330184. .
RonanHamon, PierreBorgnat, PatrickFlandrin & CélineRobardet (2016). « Relabelling vertices according to the network structure by minimizing the cyclic bandwidth sum ». Journal of Complex Networks, vol.4, n°4, pp.534-560. doi : 10.1093/comnet/cnw006. HAL : ensl-01556074.
FlorenceMagrangeas, RowanKuiper, HervéAvet-Loiseau, WilfriedGouraud, CatherineGuérin-Charbonnel, LudovicFerrer, AlexandreAussem, HaythamElghazel, JérômeSuhardet al. (2016). « A Genome-Wide Association Study Identifies a Novel Locus for Bortezomib-Induced Peripheral Neuropathy in European Multiple Myeloma Patients ». Clinical Cancer Research, Epub ahead of print. doi : 10.1158/1078-0432.CCR-15-3163. HAL : inserm-01313506. .
Conférences (25)
Conférences internationales avec comité de lecture (18)
LucianoGervasoni, MartíBosch, SergeFenet & PeterSturm (2016). « A framework for evaluating urban land use mix from crowd-sourcing data ». 2nd International Workshop on Big Data for Sustainable Development, 8 décembre 2016, Washington DC (États-Unis), pp.2147-2156. doi : 10.1109/BigData.2016.7840844. HAL : hal-01396792. .
VictorCodocedo, JaumeBaixeries, MehdiKaytoue & AmedeoNapoli (2016). « Characterization of Order-like Dependencies with Formal Concept Analysis ». Thirteenth International Conference on Concept Lattices and Their Applications (CLA 2016), 22 juillet 2016, Moscou (Russie), pp.123-134. HAL : hal-01348496. .
GuillaumeBosc, MarcPlantevit, Jean-FrançoisBoulicaut, MoustafaBensafi & MehdiKaytoue (2016). « h(odor): Interactive Discovery of Hypotheses on the Structure-Odor Relationship in Neuroscience ». ECML/PKDD 2016 (Demo), 23 septembre 2016, Riva del Garda (Italie), pp.17-21. HAL : hal-01346679. .
RaywatMakkhongkaew & KhalidBenabdeslem (2016). « Semi-supervised similarity preserving co-selection ». IEEE ICDM Workshop on High Dimensional Data Mining, 12 décembre 2016, Barcelona (Espagne).HAL : hal-01367845.
TuanNguyen, NicolasMéger, ChristopheRigotti, CatherinePothier & RémiAndréoli (2016). « SITS-P2miner: Pattern-Based Mining of Satellite Image Time Series ». European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML-PKDD) Demo, 23 septembre 2016, Riva del Garda (Italie), pp.63-66. doi : 10.1007/978-3-319-46131-1_14. HAL : hal-01367996.
JonasAbernot, GuillaumeBeslon, SimonHickinbotham, SergioPeignier & ChristopheRigotti (2016). « A Commensal Architecture for Evolving Living Instruments ». Conference on Computer Simulation of Musical Creativity, 19 juin 2016, Huddersfield (Royaume-Uni), pp.1-8. HAL : hal-01368034.
RaywatMakkhongkaew, KhalidBenabdeslem & HaythamElghazel (2016). « Semi-supervised co-selection: features and instances by a weighting approach ». International Joint Conference on Neural Networks (IJCNN 2016), 24 juillet 2016, Vancouver (Canada).HAL : hal-01340591.
OlivierCavadenti, VictorCodocedo, Jean-FrançoisBoulicaut & MehdiKaytoue (2016). « What did I do Wrong in my MOBA Game?: Mining Patterns Discriminating Deviant Behaviours ». International Conference on Data Science and Advanced Analytics, 19 octobre 2016, Montréal (Canada).HAL : hal-01388321. .
JérômeGippet, SergeFenet, AdelineDumet, BernardKaufmann & CharlesRocabert (2016). « MoRIS: Model of Routes of Invasive Spread. Human-mediated dispersal, road network and invasion parameters ». 5th International Conference on Ecology and Transportation: Integrating Transport Infrastructures with Living Landscapes, 2 septembre 2016, Lyon (France).HAL : hal-01412280.
Seif-EddineBenkabou, KhalidBenabdeslem & BrunoCanitia (2016). « Entropy-based clustering for anomaly detection from time-series data ». ICML Workshop on Anomaly detection, New York (États-Unis).HAL : hal-01340978.
OuadieGharroudi, HaythamElghazel & AlexAussem (2016). « A Semi-Supervised Ensemble Approach for Multi-label Learning ». 2016 IEEE 16th International Conference on Data Mining Workshops (ICDMW), 15 décembre 2016, Barcelona (Espagne), pp.1197-1204. HAL : hal-02018699.
AnilNarassiguin, HaythamElghazel & AlexAussem (2016). « Similarity Tree Pruning: A Novel Dynamic Ensemble Selection Approach ». 2016 IEEE 16th International Conference on Data Mining Workshops (ICDMW), 15 décembre 2016, Barcelona (Espagne), pp.1243-1250. HAL : hal-02018696.
YouenPericault, CatherinePothier, NicolasMéger, EmmanuelTrouvé, FlavienVernier, ChristopheRigotti & Jean-PhilippeMalet (2016). « Grouped frequent sequential patterns derived from terrestrial image time series tomonitor landslide behaviour – Application to the dynamics of the Sanières/Roche Plombée rockslide. ». Geophysical Research Abstracts - EGU General Assembly 2016, 22 avril 2016, Vienna (Autriche), pp.1-1. HAL : hal-01306556.
MaximeGasse & AlexAussem (2016). « Identifying the irreducible disjoint factors of a multivariate probability distribution. ». Probabilistic Graphical Models, 9 septembre 2016, Lugano (Suisse), pp.183-194. HAL : hal-01425447. .
AnesBendimerad, MarcPlantevit & CélineRobardet (2016). « Unsupervised Exceptional Attributed Sub-graph Mining in Urban Data ». IEEE International Conference on Data Mining (ICDM 2016), 15 décembre 2016, Barcelone (Espagne), pp.21-30. HAL : hal-01430622. .
MaximeGasse & AlexAussem (2016). « F-Measure Maximization in Multi-Label Classification with Conditionally Independent Label Subsets ». European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases, 23 septembre 2016, Riva del garda (Italie), pp.619-631. doi : 10.1007/978-3-319-46128-1_39. HAL : hal-01425528. .
VictorCodocedo, JaumeBaixeries, MehdiKaytoue & AmedeoNapoli (2016). « Contributions to the Formalization of Order-like Dependencies using FCA ». What can FCA do for Artificial Intelligence?, 20 août 2016, The Hague (Pays-Bas).HAL : hal-01420630. .
Conférences nationales avec comité de lecture (7)
CatherinePothier, RémiAndréoli, NicolasMéger & ChristopheRigotti (2016). « Suivi de l'érosion par imagerie satellite et fouille de données spatio-temporelles ». Journées Nationales de Géotechnique et de Géologie de l'Ingénieur, 8 juillet 2016, Nancy (France), pp.1-8. HAL : hal-01367992.
Seif-EddineBenkabou, KhalidBenabdeslem & BrunoCanitia (2016). « Une approche embedded pour la détection de nouveautés à partir de séries temporelles ». Société Francophone de Classification (SFC), Marrakech (Maroc).HAL : hal-01340981.
OlivierCavadenti, VictorCodocedo, MehdiKaytoue & Jean-FrançoisBoulicaut (2016). « Découverte de motifs intelligibles et caractéristiques d'anomalies dans les traces unitaires ». 16ème Conférence Internationale Francophone sur l'Extraction et la Gestion des Connaissances, 22 janvier 2016, Reims (France).HAL : hal-01265254. .
AimeneBelfodil, MehdiKaytoue, CélineRobardet, MarcPlantevit & JulienZarka (2016). « Une méthode de découverte de motifs contextualisés dans les traces de mobilité d'une personne ». 16ème Journées Francophones Extraction et Gestion des Connaissances, 22 janvier 2016, Reims (France), pp.63-68. HAL : hal-01265204. .
QuentinLabernia, VictorCodocedo, MehdiKaytoue & CélineRobardet (2016). « Découverte de labels dupliqués par l'exploration du treillis des classifieurs binaires ». 16 ème journées Francophones Extraction et Gestion des Connaissances, 22 janvier 2016, Reims (France), pp.255-266. HAL : hal-01265202. .
JulienSalotti, RomainBillot, Nour-EddinEl Faouzi, SergeFenet & ChristineSolnon (2016). « Vers l’utilisation de graphes de liens causaux pour l’amélioration de la prévision court-terme du trafic routier ». RFP-IA 2016 Journée Transports Intelligents, 28 juin 2016, Clermont-Ferrand (France).HAL : hal-01318166.
ThomasGärtner, MircoNanni, AndreaPasserini & CélineRobardet (2016). « ECML PKDD 2016 Journal Track Special Issue of Machine Learning ». HAL : hal-02158003.
ThomasGärtner, MircoNanni, AndreaPasserini & CélineRobardet (2016). « ECML PKDD 2016 Journal Track Special Issue ». HAL : hal-02016354.
StephaneCholet, LionelPrevost, HelenePaugam-Moisy & SébastienRegis (2016). « Affective Computing: Classification and prediction of emotional states ». Caribbean Academy Of Science, 26 novembre 2016, Deshaies (France). Poster. HAL : hal-01408029.
CyrilLanglois, ThierryDouillard, HuiYuan, NicholasBlanchard, ArmelDescamps-Mandine, BertrandVan De Moortèle, ChristopheRigotti & ThierryEpicier (2015). « Crystal orientation mapping via ion channeling: An alternative to EBSD ». Ultramicroscopy, vol.157, pp.65-72. doi : 10.1016/j.ultramic.2015.05.023. HAL : hal-01226846. .
KhalidBenabdeslem, HaythamElghazel & MohammedHindawi (2015). « Ensemble constrained Laplacian score for efficient and robust semi-supervised feature selection ». Knowledge and Information Systems (KAIS), vol.45, n°3, pp.1-25. doi : 10.1007/s10115-015-0901-0. HAL : hal-01233971.
PeggyCellier, ThierryCharnois, MarcPlantevit, ChristopheRigotti, BrunoCrémilleux, OlivierGandrillon, JiriKlema & Jean-LucManguin (2015). « Sequential pattern mining for discovering gene interactions and their contextual information from biomedical texts ». Journal of Biomedical Semantics, vol.6, pp.1-27. doi : 10.1186/s13326-015-0023-3. HAL : hal-01192959.
SylvieServigne, YannGripay, Jean-MichelDeleuil, CélineNguyen, JacquesJay, OlivierCavadenti & MebroukRadouane (2015). « Data Science approach for a cross-disciplinary understanding of urban phenomena: Application to energy efficiency of buildings ». Procedia Engineering, vol.115, pp.45-52. doi : 10.1016/j.proeng.2015.07.353. HAL : hal-01192716. .
AbdelouahidAlalga, KhalidBenabdeslem & NoraTaleb (2015). « Soft-Constrained Laplacian score for semi-supervised multi-label feature selection ». Knowledge and Information Systems (KAIS), vol.43, n°3, pp.1-24. doi : 10.1007/s10115-015-0841-8. HAL : hal-01195540.
KhalidBenabdeslem, ChristopheBiernacki & MustaphaLebbah (2015). « Les trois défis du Big-Data: Eléments de reflexion ». Statistique et Société, vol.3, n°1, pp.19-22. HAL : hal-01198435.
Autres revues (1)
RaywatMakkhongkaew, StéphaneBonnevay, AlexAussem & KhalidBenabdeslem (2015). « Classification model for performance diagnosis of dry port by rail ». Journal of Society for Transportation and Traffic Studies, vol.6, n°2, pp.31-40. HAL : hal-01134826. .
Conférences (29)
Conférences internationales avec comité de lecture (22)
CyrilLanglois, ThierryDouillard, HuiYuan, NicholasBlanchard, ArmelDescamps-Mandine, BertrandVan De Moortèle, ChristopheRigotti, ThierryEpicier & SébastienDubail (2015). « Crystal Orientation Mapping using ion image series: iCHORD ». EUROMAT, 20 septembre 2015, Warsaw (Pologne).HAL : hal-02066188.
MaximeGasse, AlexAussem & HaythamElghazel (2015). « On the Optimality of Multi-Label Classification under Subset Zero-One Loss for Distributions Satisfying the Composition Property ». International Conference on Machine Learning, 11 juillet 2015, Lille (France), pp.2531-2539. HAL : hal-01234346. .
CyrilLanglois, ThierryDouillard, HuiYuan, NicholasBlanchard, ArmelDescamps-Mandine, BertrandVan De Moortèle, ChristopheRigotti & ThierryEpicier (2015). « Crystal orientation mapping via ion channeling: an alternative to EBSD ». Microscience Microscopy Congress 2015, 25 juin 2015, Manchester (Royaume-Uni).HAL : hal-02066168.
VictorCodocedo & AmedeoNapoli (2015). « Formal Concept Analysis and Information Retrieval – A Survey ». International Conference in Formal Concept Analysis - ICFCA 2015, 26 juin 2015, Nerja (Espagne), pp.61-77. doi : 10.1007/978-3-319-19545-2_4. HAL : hal-01186196. .
SergioPeignier, ChristopheRigotti & GuillaumeBeslon (2015). « Subspace Clustering Using Evolvable Genome Structure ». Genetic and Evolutionary Computation Conference (GECCO), 11 juillet 2015, Madrid (Espagne), pp.575-582. HAL : hal-01199136.
MehwishAlam, AlekseyBuzmakov, VictorCodocedo & AmedeoNapoli (2015). « Mining Definitions from RDF Annotations Using Formal Concept Analysis ». International Joint Conference in Artificial Intelligence, 31 juillet 2015, Buenos Aires (Argentine).HAL : hal-01186204. .
OuadieGharroudi, HaythamElghazel & AlexAussem (2015). « Calibrated k-labelsets for Ensemble Multi-Label Classification ». International Conference on Neural Information Processing, 12 novembre 2015, Istanbul (Turquie), pp.573-582. HAL : hal-01375166.
Van-TinhTran & AlexAussem (2015). « A Practical Approach to Reduce the Learning Bias Under Covariate Shift ». ECML PKDD 2015 - European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases, 11 septembre 2015, Porto (Portugal), pp 71-86. doi : 10.1007/978-3-319-23525-7_5. HAL : hal-01213965. .
NicolasMéger, ChristopheRigotti & CatherinePothier (2015). « Swap Randomization of Bases of Sequences for Mining Satellite Image Time Series ». European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML PKDD), 11 septembre 2015, Porto (Portugal), pp.190-205. HAL : hal-01200674.
RonanHamon, PierreBorgnat, CédricFévotte, PatrickFlandrin & CélineRobardet (2015). « Factorisation de réseaux temporels : étude des rythmes hebdomadaires du système Vélo'v ». Colloque GRETSI 2015, 12 septembre 2015, Lyon (France).HAL : hal-01199256. .
Van-TinhTran & AlexAussem (2015). « Correcting a Class of Complete Selection Bias with External Data Based on Importance Weight Estimation ». 22nd International Conference, ICONIP 2015, 12 novembre 2015, Istanbul (Turquie).doi : 10.1007/978-3-319-26555-1_13. HAL : hal-01247394. .
KhalidBenabdeslem, MohammedHindawi & RaywatMakkhongkaew (2015). « Weighting-based approach for semi-supervised feature selection ». International Conference on Neural Information Processing, 9 novembre 2015, Istanbul (Turquie).HAL : hal-01198437.
MartínBarrère, GustavoBetarte, VictorCodocedo, MarceloRodríguez, HernánAstudillo, MarceloAliquintuy, JavierBaliosian, RémiBadonnel, OlivierFestoret al. (2015). « Machine-assisted Cyber Threat Analysis using Conceptual Knowledge Discovery ». FCA4AI 2015 - Workshop What can FCA do for Artificial Intelligence?, 25 juillet 2015, Buenos Aires (Argentine), pp.75-85. HAL : hal-01186213. .
MehdiKaytoue, VictorCodocedo, AlekseyBuzmakov, JaumeBaixeries, SergeiKuznetsov & AmedeoNapoli (2015). « Pattern Structures and Concept Lattices for Data Mining and Knowledge Processing ». Machine Learning and Knowledge Discovery in Databases - European Conference, ECMLPKDD 2015, Porto, Portugal, September 7-11, 2015, Proceedings., Porto (Portugal), pp.227-231. doi : 10.1007/978-3-319-23461-8_19. HAL : hal-01188637.
HoudyerPierre, AlbrechtZimmermann, MehdiKaytoue, MarcPlantevit, JosephMitchell & CélineRobardet (2015). « Gazouille: Detecting and Illustrating Local Events from Geolocalized Social Media Streams ». European Conference on Machine Learning and Knowledge Discovery in Databases, Porto (Portugal), pp.276-280. doi : 10.1007/978-3-319-23461-8_29. HAL : hal-01193030.
LeonGaillard, GuillaumeRuedin, StéphanieGiroux-Julien, MarcPlantevit, MehdiKaytoue, SyamimiSaadon, ChristopheMénézo & Jean-FrançoisBoulicaut (2015). « Data-driven performance evaluation of ventilated photovoltaic double-skin facades in the built environment ». 6th International Building Physics Conference, 17 juin 2015, Turin (Italie), pp.447-452. doi : 10.1016/j.egypro.2015.11.694. HAL : hal-01272611. .
JérômeGippet, CharlesRocabert, SergeFenet, AdelineDumet & BernardKaufmann (2015). « Modeling and evaluating human-mediated dispersal mechanisms at landscape scale: a study of road network and invasion parameters for Lasius neglectus ants invasive species ». World Conference on Natural Resource Modeling, 1 juillet 2015, Bordeaux (France).HAL : hal-01242828. .
OuadieGharroudi, HaythamElghazel & AlexAussem (2015). « Ensemble Multi-label Classification: A Comparative Study on Threshold Selection and Voting Methods ». IEEE International Conference on Tools with Artificial Intelligence,, 11 novembre 2015, Vietri sul Mare (Italie), pp.377-384. HAL : hal-01375164.
YouenPericault, CatherinePothier, NicolasMeger, ChristopheRigotti, FlavienVernier, Ha-TaiPham & EmmanuelTrouvé (2015). « A swap randomization approach for mining motion field time series over the Argentiere glacier ». 2015 8th International Workshop on the Analysis of Multitemporal Remote Sensing Images (Multi-Temp), 24 juillet 2015, Annecy (France), pp.1-4. doi : 10.1109/Multi-Temp.2015.7245757. HAL : hal-01237206.
Conférences nationales avec comité de lecture (7)
LeonGaillard, GuillaumeRuedin, StéphanieGiroux-Julien, MarcPlantevit, MehdiKaytoue, ChristopheMenezo & Jean-FrançoisBoulicaut (2015). « Fouille de données pour l’analyse du comportement complexe de systèmes photovoltaïque-thermiques en vrai grandeur et in situ intégrés aux bâtiments ». Congrès français de thermique, la thermique de l'habitat et de la ville, 29 mai 2015, La Rochelle (France).HAL : hal-01478948.
GuillaumeBosc, MehdiKaytoue, MarcPlantevit, FabienDe Marchi, MoustafaBensafi & Jean-FrançoisBoulicaut (2015). « Vers la découverte de modèles exceptionnels locaux : des règles descriptives liant les molécules à leurs odeurs ». 15e Journées Internationales Francophones Extraction et Gestion des Connaissances (EGC 2015), 30 janvier 2015, Luxembourg (Luxembourg), pp.305-316. HAL : hal-01346739. .
LéonGaillard, GuillaumeRuedin, StéphanieGiroux-Julien, MarcPlantevit, MehdiKaytoue, SyamimiSaadon, ChristopheMénézo & Jean-FrançoisBoulicaut (2015). « Evaluation des performances réelles de double‑peaux PV ventilées en milieu urbain suivant une approche orientée données, ». XIIe Colloque Inter-Universitaire Franco-Québécois, 10 juin 2015, Sherbrooke (Canada), pp.01-09. HAL : hal-01478901.
LéonGaillard, GuillaumeRuedin, StéphanieGiroux-Julien, MarcPlantevit, MehdiKaytoue, SyamimiSaadon, ChristopheMénézo & Jean-FrançoisBoulicaut (2015). « Évaluation des performances réelles de double-peaux PV ventilées en milieu urbain suivant une approche orientée données ». 2e journées nationales de l’énergie solaire - JNES 2015, 3 juillet 2015, Perpignan (France).HAL : hal-01479040.
Seif-EddineBenkabou, KhalidBenabdeslem & BrunoCanitia (2015). « Une approche à deux niveaux séquentiels pour la détection de nouveautés à partir de séries temporelles ». 22ème Rencontres de la Société Francophone de Classification, 9 septembre 2015, Nantes (France), pp.129-132. HAL : hal-01198439.
AbderrahmaneBendahmane, AbdelkaderBenyettou & KhalidBenabdeslem (2015). « Une approche évolutionnaire multi-contraintes pour l'optimisation de la génération automatique d'emplois du temps universitaires ». Colloque sur l'Optimisation et les Systèmes d'Information, 1 juin 2015, Oran (Algérie).HAL : hal-01198440.
AssiaBenyettou, AbderrahmaneBendahmane & KhalidBenabdeslem (2015). « Sélection de variables pour l'amélioration de l'accès à l'information sur le Web ». Colloque sur l'Optimisation et les Systèmes d'Information, 1 juin 2015, Oran (France).HAL : hal-01198442.
Rapports (1)
Rapports de recherche/technique (1)
RonanHamon, PierreBorgnat, PatrickFlandrin & CélineRobardet (2015). « Discovering the structure of complex networks: Implementation and Complexity of the heuristic MACH ». Rapport technique. HAL : ensl-01160737. .
MarieVogel, RonanHamon, GuillaumeLozenguez, LucMerchez, PatriceAbry, JulienBarnier, PierreBorgnat, PatrickFlandrin, IsabelleMallon & CélineRobardet (2014). « From bicycle sharing system movements to users: a typology of Vélo’v cyclists in Lyon based on large-scale behavioural dataset ». Journal of Transport Geography, vol.41, pp.280-291. doi : 10.1016/j.jtrangeo.2014.07.005. HAL : hal-01313177.
KhalidBenabdeslem & MohammedHindawi (2014). « Efficient semi-supervised feature selection: Constraint, Relevance and Redundancy. ». IEEE Transactions on Knowledge and Data Engineering, vol.26, pp.1131-1143. doi : 10.1109/TKDE.2013.86. HAL : hal-01301033.
MehdiKaytoue, SergeiKuznetsov, JurajMacko & AmedeoNapoli (2014). « Biclustering meets triadic concept analysis ». Annals of Mathematics and Artificial Intelligence, vol.70, pp.55-79. doi : 10.1007/s10472-013-9379-1. HAL : hal-01101143. .
JaumeBaixeries, MehdiKaytoue & AmedeoNapoli (2014). « Characterizing functional dependencies in formal concept analysis with pattern structures ». Annals of Mathematics and Artificial Intelligence, vol.72, pp.129-149. doi : 10.1007/s10472-014-9400-3. HAL : hal-01101107. .
JérômePrunier, BernardKaufmann, Jean-PaulLéna, SergeFenet, FrancoisPompanon & PierreJoly (2014). « A 40-year-old divided highway does not prevent gene flow in the alpine newt Ichthyosaura alpestris ». Conservation Genetics, vol.15, n°2, pp.453-468. doi : 10.1007/s10592-013-0553-0. HAL : halsde-00968131. .
Conférences internationales avec comité de lecture (16)
SergeFenet, YannickPerret & JulienSalotti (2014). « Extract space-time dynamics from sensor network to build urban traffic prediction model: a machine learning point of view ». Urban Modelling Symposium, 17 octobre 2014, Lyon (France).HAL : hal-01241516. .
EliseDesmier, MarcPlantevit, CélineRobardet & Jean-FrançoisBoulicaut (2014). « Granularity of co-Evolution Patterns in Dynamic Attributed Graphs ». The Thirteenth International Symposium on Intelligent Data Analysis IDA 2014, 30 octobre 2014, Leuven (Belgique), pp.84-95. HAL : hal-01301086.
AlexAussem, PascalCaillet, SarahKlemm, MaximeGasse, Anne-MarieSchott & MichelDucher (2014). « Analysis of risk factors of hip fracture with causal Bayesian networks ». International Work-Conference on Bioinformatics and Biomedical Engineering, 7 avril 2014, Grenade (Espagne), pp.1074-1085. HAL : hal-01326485.
MehdiKaytoue, YoannPitarch, MarcPlantevit & CélineRobardet (2014). « Triggering Patterns of Topology Changes in Dynamic Graphs ». The 2014 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, 17 août 2014, Beijing, China (Chine), 55:1-55:17. doi : 10.1109/ASONAM.2014.6921577. HAL : hal-01301075.
OuadieGharroudi, HaythamElghazel & AlexAussem (2014). « A Comparison of Multi-Label Feature Selection Methods Using the Random Forest Paradigm ». Canadian Conference on Artificial Intelligence, AI, 6 mai 2014, Montréal (Canada), pp.95-106. HAL : hal-01301070.
RanaChamsi Abu Quba, SalimaHassas, HammamChamsi & UsamaFayyad (2014). « From a “Cold” to a “Warm” Start in Recommender systems ». IEEE International Conference on Enabling Technologies: Infrastructure for Collaborative Enterprises (WETICE 2014), 23 juin 2014, Parma (Italie), pp.1-7. doi : 10.1109/WETICE.2014.66. HAL : hal-01301058.
JaumeBaixeries, MehdiKaytoue & AmedeoNapoli (2014). « Characterization of Database Dependencies with FCA and Pattern Structures ». Third International Conference, Analysis of Images, Social Networks and Texts (AIST 2014), Yekaterinburg (Russie), pp.3-14. doi : 10.1007/978-3-319-12580-0_1. HAL : hal-01101147. .
PierreHolat, MarcPlantevit, ChedyRaïssi, NadiTomeh, ThierryCharnois & BrunoCrémilleux (2014). « Sequence Classification Based on Delta-Free Sequential Pattern ». IEEE International Conference on Data Mining, 17 décembre 2014, Shenzhen (Chine).HAL : hal-01100929. .
FelicityLodge, NicolasMeger, ChristopheRigotti, CatherinePothier & Marie-PierreDoin (2014). « Iterative Summarization of Satellite Image Time Series ». IEEE International Geoscience and Remote Sensing Symposium (IGARSS 2014), Québec (Canada), pp.1-4. HAL : hal-01091940.
MarcPlantevit, Vasile-MarianScuturici & CélineRobardet (2014). « Temporal Dependency Detection Between Interval-Based Event Sequences ». New Frontiers in Mining Complex Patterns - Third International Workshop, NFMCP, Held in Conjunction with ECML-PKDD, Nancy, France, Revised Selected Papers, 19 septembre 2014, Nancy (France), pp.132-146. HAL : hal-01979495.
Günce KezibanOrman, VincentLabatut, MarcPlantevit & Jean-FrançoisBoulicaut (2014). « A Method for Characterizing Communities in Dynamic Attributed Complex Networks ». IEEE/ACM International Conference on Advances in Social Network Analysis and Mining (ASONAM), 20 août 2014, Pékin (Chine), pp.481-484. doi : 10.1109/ASONAM.2014.6921629. ArXiv : 1406.6597. HAL : hal-01011913. .
RonanHamon, PierreBorgnat, PatrickFlandrin & CélineRobardet (2014). « Nonnegative matrix factorization to find features in temporal networks ». 2014 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 9 mai 2014, Florence (Italie), SPTM-P4.1. HAL : ensl-00989760. .
SylvieServigne, YannGripay, Jean-MichelDeleuil, JacquesJay, OlivierCavadenti & RadouaneMebrouk (2014). « Data Science approach for a cross-disciplinary understanding of urban phenomena : Application to energy efficiency of buildings based on physical measures and user behaviours ». Urban Modelling Symposium : Towards Integrated Modelling of Urban Systems, 15 octobre 2014, Lyon - 15-17 octobre 2014 (France), pp.1-6. HAL : hal-01499281.
MehdiKaytoue, VictorCodocedo, JaumeBaixeries & AmedeoNapoli (2014). « Three Related FCA Methods for Mining Biclusters of Similar Values on Columns ». Proceedings of the Eleventh International Conference on Concept Lattices and Their Applications, Kosice, Slovakia, October 7-10, 2014, 10 octobre 2014, Kosice (Slovaquie).HAL : hal-01095877. .
FrédéricFlouvat, JérémySanhes, ClaudePasquier, NazhaSelmaoui-Folcher & Jean-FrançoisBoulicaut (2014). « Improving pattern discovery relevancy by deriving constraints from expert models ». European Conference on Artificial Intelligence (ECAI'2014), 22 août 2014, Prague (République Tchèque), pp.327-332. doi : 10.3233/978-1-61499-419-0-327. HAL : hal-01151514. .
Conférences nationales avec comité de lecture (4)
AbdelouahidAlalga & KhalidBenabdeslem (2014). « Sélection de variables en mode semi-supervisé dans un contexte multi-labels ». Conférence francophone d’apprentissage, CAp 2014, 10 juillet 2014, Saint-Etienne (France).HAL : hal-01588285.
FrédéricFlouvat, JérémySanhes, ClaudePasquier, NazhaSelmaoui-Folcher & Jean-FrançoisBoulicaut (2014). « Les modèles des experts au service de l'extraction de motifs pertinents ». Reconnaissance de Formes et Intelligence Artificielle (RFIA) 2014, 30 juin 2014, ROUEN (France).HAL : hal-00989223. .
Günce KezibanOrman, VincentLabatut, MarcPlantevit & Jean-FrançoisBoulicaut (2014). « Une méthode pour caractériser les communautés des réseaux dynamiques à attributs ». 14ème Conférence Extraction et Gestion des Connaissances (EGC), 31 janvier 2014, Rennes (France), pp.101-112. ArXiv : 1312.4676. HAL : hal-00918181. .
ChristopheRigotti, FelicityLodge, NicolasMéger, CatherinePothier, RomainJolivet & CécileLasserre (2014). « Monitoring of Tectonic Deformation by Mining Satellite Image Time Series ». Reconnaissance de Formes et Intelligence Artificielle (RFIA) 2014, 4 juillet 2014, Rouen (France), pp.1-6. HAL : hal-00988907. .
Autres conférences (2)
GuillaumeBosc, MehdiKaytoue, ChedyRaïssi & Jean-FrançoisBoulicaut (2014). « Fouille de motifs séquentiels pour l'élicitation de stratégies à partir de traces d'interactions entre agents en compétition ». Extraction et Gestion de Connaissances EGC 2014, 28 janvier 2014, Rennes (France), pp.359-370. HAL : hal-01270794.
EliseDesmier, MarcPlantevit & Jean-FrançoisBoulicaut (2014). « Granularité des motifs de co-variation dans des graphes attribués dynamiques. ». Extraction et Gestion des Connaissances EGC 2014, 30 janvier 2014, Rennes (France), pp.431-442. HAL : hal-01270736.
RanaChamsi Abu Quba, SalimaHassas, FayyadUsama, HammamChamsi & ChristineGertosio (2014). « iSoNTRE : The Intelligent Social Network Transformer into Recommendation Engine framework ». iSoNTRE : Transformateur Intelligent de Réseaux Sociaux en Plateforme de Moteur de Recommandation, Hermès Sciences. HAL : hal-01552137.
SébastienRebecchi, HélènePaugam-Moisy & MichèleSebag (2014). « Learning Sparse Features with an Auto-Associator ». Growing Adaptive Machines, Kowaliw, Taras and Bredeche, Nicolas and Doursat, René, Springer Verlag, pp.139-158. doi : 10.1007/978-3-642-55337-0_4. HAL : hal-01109773. .
Autres (1)
Cynthia VeraGlodeanu, MehdiKaytoue & ChristianSacarea (2014). « Formal Concept Analysis - Proceedings of the 12th International Conference (ICFCA 2014) ». doi : 10.1007/978-3-319-07248-7. HAL : hal-01314560.
2013 (26)
Revues (6)
Revues internationales avec comité de lecture (6)
LoicCerf, DominiqueGay, NazhaSelmaoui-Folcher, BrunoCrémilleux & Jean-FrançoisBoulicaut (2013). « Parameter-free classification in multi-class imbalanced data sets ». Data and Knowledge Engineering, vol.87, n°9, pp.109-129. doi : 10.1016/j.datak.2013.06.001. HAL : hal-01024631. .
AdrianaPrado, BaptisteJeudy, ElisaFromont & FabienDiot (2013). « Mining Spatiotemporal Patterns in Dynamic Plane Graphs ». Intelligent Data Analysis, vol.17, n°1, pp.71-92. HAL : ujm-00629121.
JérômePrunier, BernardKaufmann, SergeFenet, DamienPicart, FrancoisPompanon & Jean-PaulLéna (2013). « Optimizing the trade-off between spatial and genetic sampling efforts in patchy populations: towards a better assessment of functional connectivity using an individual-based sampling scheme ». Molecular Ecology, vol.22, pp.5516-5530. doi : 10.1111/mec.12499. HAL : halsde-00942596.
Thi Kim NganNguyen, LoicCerf, MarcPlantevit & Jean-FrançoisBoulicaut (2013). « Discovering Descriptive Rules in Relational Dynamic Graphs ». Intelligent Data Analysis, vol.17, pp.49-69. HAL : hal-01351698.
LoicCerf, JérémyBesson, Thi Kim NganNguyen & Jean-FrançoisBoulicaut (2013). « Closed and Noise-Tolerant Patterrns in N-ary Relations. ». Data Mining and Knowledge Discovery, vol.26, pp.574-619. doi : 10.1007/s10618-012-0284-8. HAL : hal-01339130.
Conférences (18)
Conférences internationales avec comité de lecture (12)
CécileLow-Kam, ChedyRaïssi, MehdiKaytoue & JianPei (2013). « Mining Statistically Significant Sequential Patterns ». IEEE International Conference on Data Mining, 10 décembre 2013, Dallas (États-Unis).HAL : hal-00922255.
AdrienCoulet, FlorentDomenach, MehdiKaytoue & AmedeoNapoli (2013). « Using Pattern Structures for Analyzing Ontology-Based Annotations of Biomedical Data ». International Conference on Formal Concept Analysis, 24 mai 2013, Dresden (Allemagne).HAL : hal-00880643. .
RonanHamon, PierreBorgnat, PatrickFlandrin & CélineRobardet (2013). « Tracking of a dynamic graph using a signal theory approach : application to the study of a bike sharing system ». ECCS'13, 20 septembre 2013, Barcelone (Espagne), p.101. HAL : ensl-00875089. .
RonanHamon, PierreBorgnat, PatrickFlandrin & CélineRobardet (2013). « Networks as Signals, with an Application to Bike Sharing System ». GlobalSIP 2013, 5 décembre 2013, Austin (États-Unis), IPN.PB.8. HAL : ensl-00875187. .
JaumeBaixeries, MehdiKaytoue & AmedeoNapoli (2013). « Computing Similarity Dependencies with Pattern Structures ». The Tenth International Conference on Concept Lattices and their Applications - CLA 2013,, La Rochelle, France (France), pp.33-44. HAL : hal-00922592. .
MohammedHindawi, HaythamElghazel & KhalidBenabdeslem (2013). « Efficient semi-supervised feature selection by an ensemble approach ». International Workshop on Complex Machine Learning Problems with Ensemble Methods COPEM@ECML/PKDD'13, 27 septembre 2013, Prague (République Tchèque), pp.41-55. HAL : hal-01339249.
MohamedBibimoune, HaythamElghazel & AlexAussem (2013). « An Empirical Comparison of Supervised Ensemble Learning Approaches ». International Workshop on Complex Machine Learning Problems with Ensemble Methods COPEM@ECML/PKDD'13, 27 septembre 2013, Prague (République Tchèque), pp.123-138. HAL : hal-01339258.
MohammedHindawi & KhalidBenabdeslem (2013). « Local-To-Global Semi-Supervised Feature selection ». ACM International Conference on Information and Knowledge Management (CIKM 2013), 27 octobre 2013, San Fransisco CA (États-Unis), pp.2159-2168. doi : 10.1145/2505515.2505542. HAL : hal-01339244.
JérémySanhes, FrédéricFlouvat, NazhaSelmaoui-Folcher, ClaudePasquier & Jean-FrançoisBoulicaut (2013). « Weighted Path as a Condensed Pattern in a Single Attributed DAG ». 23rd International Joint Conference on Artificial Intelligence (IJCAI'13), 9 août 2013, Beijing (Chine), pp.1642-8. HAL : hal-01151561. .
Jean-FrançoisBoulicaut (2013). « New applications of Formal Concept Analysis: a Need for New Pattern Domains ». Formal Concept Analysis meets Information Retrieval FCAIR 2013 co-located with ECIR, 24 mars 2013, Moscow, Russia, 24th March 2013 (Russie), pp.2-4. HAL : hal-01339184.
Conférences nationales avec comité de lecture (6)
AdrienCoulet, FlorentDomenach, MehdiKaytoue & AmedeoNapoli (2013). « Using pattern structures for analyzing ontology-based annotations of biomedical data ». Septièmes Journées d'Intelligence Artificielle Fondamentale, 14 juin 2013, Aix-en-Provence (France), pp.97-106. HAL : hal-00922392. .
RonanHamon, PierreBorgnat, PatrickFlandrin & CélineRobardet (2013). « Transformation de graphes dynamiques en signaux non stationnaires ». Colloque GRETSI 2013, 6 septembre 2013, Brest (France), p.251. HAL : ensl-00875085. .
ChristopheRigotti, NicolasMeger, FelicityLodge & CatherinePothier (2013). « Fouille de données spatio-temporelles appliquée aux séries d'images satellite ». Cité des Sciences et de l'Industrie - Rencontres du Numérique de l'ANR, 17 avril 2013, Paris (France).HAL : hal-01339286.
FelicityLodge, NicolasMeger, ChristopheRigotti, LionelGueguen, CatherinePothier, RemiAndreoli, Marie-PierreDoin & MihaiDatcu (2013). « GFS-pattern extraction in satellite image time series: application to the monitoring of Mount Etna ». Atelier Mesure de Déformations par Imagerie Spatiale, 17 octobre 2013, Autrans (France), pp.1-1. HAL : hal-01339287.
JérémySanhes, FrédéricFlouvat, ClaudePasquier, NazhaSelmaoui-Folcher & Jean-FrançoisBoulicaut (2013). « Extraction de motifs condensés dans un seul graphe orienté acyclique attribué ». Actes Extraction et Gestion de Connaissances EGC'13, 29 janvier 2013, Toulouse (France), pp.205-216. HAL : hal-01339162.
JérémySanhes, FrédéricFlouvat, ClaudePasquier, NazhaSelmaoui-Folcher & Jean-FrançoisBoulicaut (2013). « Extraction de motifs condensés dans un unique graphe orienté acyclique attribué ». 13e Conférence Francophone sur l'Extraction et la Gestion des Connaissances (EGC'13), 1 février 2013, Toulouse (France).HAL : hal-01151510. .
HDR, thèses (1)
HDR (1)
CélineRobardet (2013). « Constraint-based pattern mining approaches for the analysis of relational attributed dynamic graphs ». HAL : hal-01478974. .
PierreBorgnat, CélineRobardet, PatriceAbry, PatrickFlandrin, Jean-BaptisteRouquier & NicolasTremblay (2013). « A Dynamical Network View of Lyon's Vélo'v Shared Bicycle System ». Dynamics On and Of Complex Networks, Volume 2: Applications to Time-Varying Dynamical Systems, A. Mukherjee, M. Choudhury, F. Peruani, N. Ganguly, B. Mitra, springer, pp.267-284. HAL : hal-01339131.
2012 (19)
Revues (5)
Revues internationales avec comité de lecture (5)
AndreeaJulea, NicolasMéger, ChristopheRigotti, EmmanuelTrouvé, RomainJolivet & PhilippeBolon (2012). « Efficient Spatiotemporal Mining of Satellite Image Time Series for Agricultural Monitoring ». Transactions on Machine Learning and Data Mining, vol.5, n°1, pp.23-44. HAL : hal-00702433.
HendrikBlockeel, ToonCalders, ElisaFromont, BartGoethals, AdrianaPrado & CélineRobardet (2012). « An Inductive Database System Based on Virtual Mining Views ». Data Mining and Knowledge Discovery, vol.24, n°1, pp.265-287. doi : 10.1007/s10618-011-0229-7. HAL : hal-00599315. .
Conférences internationales avec comité de lecture (9)
Pierre-NicolasMougel, ChristopheRigotti & OlivierGandrillon (2012). « Finding Collections of k-Clique Percolated Components in Attributed Graphs ». Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD), Kuala Lumpur (Malaisie), pp.181-192. HAL : hal-00758843.
Thanh-HuyLe, HaythamElghazel & Mohand-SaidHacid (2012). « A Relational-Based Approach for Aggregated Search in Graph Databases ». International Conference on Database Systems for Advanced Applications (DASFAA 2012), 15 avril 2012, Busan (Corée du Sud), pp.33-47. doi : 10.1007/978-3-642-29038-1_5. HAL : hal-01353115.
Pierre-NicolasMougel, ChristopheRigotti & OlivierGandrillon (2012). « Finding Collections of Protein Modules in Protein-Protein Interaction Networks ». Bioinformatics and Computational Biology (BICoB), Las Vegas (États-Unis), pp.216-222. HAL : hal-00758858.
JaumeBaixeries, MehdiKaytoue & AmedeoNapoli (2012). « Computing Functional Dependencies with Pattern Structures ». The 9th International Conference on Concept Lattices and Their Applications - CLA 2012, 14 octobre 2012, Malaga (Espagne).HAL : hal-00763748.
FlorentArthaud, SergeFenet & AdrianaPrado (2012). « Mining co-variation patterns from ecological data: a process to aid the construction and validation of computer models ». CompSust2012 : 3rd International Conference on Computational Sustainability, 4 juin 2012, University of Copenhagen (Danemark), pp.1-3. HAL : hal-01352996.
Thi Kim NganNguyen, MarcPlantevit & Jean-FrançoisBoulicaut (2012). « Mining Disjunctive Rules in Dynamic Graphs ». 2012 IEEE RIVF International Conference on Computing and Communication Technologies, Research, Innovation, and Vision for the Future (RIVF), 27 février 2012, Ho Chi Minh (Viêt Nam), pp.74-79. doi : 10.1109/rivf.2012.6169829. HAL : hal-01352944.
JérômePrunier, SergeFenet, FrançoisPompanon, PierreJoly, BernardKaufmann & Jean-PaulLéna (2012). « The individual-level approach: an original genetic field sampling scheme to optimize barrier detection in patchy populations ». IENE 2012, international conference on ecology and transportation, 21 octobre 2012, Postdam-Berlin (Allemagne), inconnue. HAL : hal-01353154.
NicolasMeger, ChristopheRigotti, LionelGueguen, FelicityLodge, CatherinePothier, RemiAndreoli & MihaiDatcu (2012). « Normalized Mutual Information-Based Ranking of Spatio-Temporal Localization Maps ». 8th European Spatial Agency (ESA) - EUSC - JRC Conference on Image Information Mining, 24 octobre 2012, Oberpfaffenhofen (Allemagne), pp.11-14. HAL : hal-01353105.
MohammedHindawi & KhalidBenabdeslem (2012). « Une approche embedded pour la sélection de variables en mode semi-supervisé ». Société Française de Classification (SFC), 29 octobre 2012, Marseille (France), p.13. HAL : hal-01353114.
AdrianaBechara Prado, MarcPlantevit, CélineRobardet & Jean-FrançoisBoulicaut (2012). « Extraction de co-variations entre des propriétés de sommets et leur position topologique dans un graphe attribué. ». Actes Extraction et Gestion de Connaissances EGC'12, 31 janvier 2012, Bordeaux (France), pp.267-278. HAL : hal-01352957.
JérémySanhes, FrédéricFlouvat, NazhaSelmaoui-Folcher & Jean-FrançoisBoulicaut (2012). « Extraction d'arbres spatio-temporels d'itemsets pour le suivi environnemental. ». Actes Extraction et Gestion de Connaissances EGC'12, 31 janvier 2012, Bordeaux (France), pp.581-582. HAL : hal-01353067.
HélènePaugam-Moisy & Sander M.Bohte (2012). « Computing with Spiking Neuron Networks ». Handbook of Natural Computing, G. Rozenberg, T. Back, J. Kok, Springer-Verlag, pp.335-376. doi : 10.1007/978-3-540-92910-9_10. HAL : hal-01587781.
Autres (1)
JulienSalotti, MarcPlantevit, CélineRobardet & Jean-FrançoisBoulicaut (2012). « Supporting the Discovery of Relevant Topological Patterns in Attributed Graphs ». Demo Session of the IEEE International Conference on Data Mining (IEEE ICDM 12), 10 décembre 2012, Brussels (Belgique). Poster. doi : 10.1109/ICDMW.2012.38. HAL : hal-01353106.
2011 (20)
Revues (4)
Revues internationales avec comité de lecture (4)
PierreBorgnat, CélineRobardet, Jean-BaptisteRouquier, PatriceAbry, EricFleury & PatrickFlandrin (2011). « Shared Bicycles in a City: A Signal Processing and Data Analysis Perspective ». Advances in Complex Systems (ACS), vol.14, n°3, pp.415-438. doi : 10.1142/S0219525911002950. HAL : ensl-00490325. .
AndreeaJulea, NicolasMéger, PhilippeBolon, ChristopheRigotti, Marie-PierreDoin, CécileLasserre, EmmanuelTrouvé & Vasile N.Lazarescu (2011). « Unsupervised Spatiotemporal Mining of Satellite Image Time Series Using Grouped Frequent Sequential Patterns ». IEEE Transactions on Geoscience and Remote Sensing, vol.49, n°4, pp.1417-1430. doi : 10.1109/TGRS.2010.2081372. HAL : hal-00596806.
MaurizioDe Pittà, VladislavVolman, HuguesBerry & EshelBen-Jacob (2011). « A tale of two stories: astrocyte regulation of synaptic depression and facilitation ». PLoS Computational Biology, vol.7, n°12, e1002293. doi : 10.1371/journal.pcbi.1002293. HAL : inria-00633588. .
DominiqueGay, NazhaSelmaoui-Folcher & Jean-FrançoisBoulicaut (2011). « Application-Independent Feature Construction Based onAlmost-Closedness Properties ». Knowledge and Information Systems (KAIS), vol.30, pp.87-111. HAL : hal-01354374.
Conférences (14)
Conférences internationales avec comité de lecture (11)
AndreeaJulea, FernandaLedo, NicolasMéger, EmmanuelTrouvé, PhilippeBolon, ChristopheRigotti, RenaudFallourd, Jean-MarieNicolas, GabrielVasileet al. (2011). « Polsar Radarsat-2 Satellite Image Time Series Mining Over the Chamonix Mont-Blanc Test Site ». IGARSS 2011 - IEEE International Geoscience and Remote Sensing Symposium, 29 juillet 2011, Vancouver (Canada), pp 1191-1194. HAL : hal-00620881.
AndreeaJulea, NicolasMéger, ChristopheRigotti, EmmanuelTrouvé, PhilippeBolon & VasileLazarescu (2011). « Mining Pixel Evolutions in Satellite Image Time Series for Agricultural Monitoring ». 11th Industrial Conference on Data Mining ICDM 2011, 3 septembre 2011, New-York (États-Unis), pp.189-203. doi : 10.1007/978-3-642-23184-1_15. HAL : hal-00620882.
NicolasMéger, RomainJolivet, CécileLasserre, EmmanuelTrouvé, ChristopheRigotti, FelicityLodge, M. P.Doin, StéphaneGuillaso, AndreeaJulea & PhilippeBolon (2011). « Spatio-Temporal Mining of ENVISAT SAR Interferogram Time Series over the Haiyuan Fault in China ». 2011 6th International Workshop on the Analysis of Multi-temporal Remote Sensing Images (Multi-Temp), 14 juillet 2011, Trento (Italie), 10.1109/Multi-Temp.2011.6005067. doi : 10.1109/Multi-Temp.2011.6005067. HAL : hal-00621236.
Thi Kim NganNguyen, LoicCerf, MarcPlantevit & Jean-FrançoisBoulicaut (2011). « Multidimensional Association Rules in Boolean Tensors ». 11th SIAM International Conference on Data Mining SDM'11, 28 avril 2011, Phoenix, Arizona (États-Unis), pp.570-581. doi : 10.1137/1.9781611972818.49. HAL : hal-01354377.
EliseDesmier, FrédéricFlouvat, DominiqueGay & NazhaSelmaoui-Folcher (2011). « A clustering-based visualization of colocation patterns ». 15th International Database Engineering and Applications Symposium (IDEAS 2011), 27 septembre 2011, Lisbonne (Portugal), pp.70-78. HAL : hal-01464494.
ArnaudSoulet, ChedyRaïssi, MarcPlantevit & BrunoCrémilleux (2011). « Mining Dominant Patterns in the Sky ». The 11th IEEE International Conference on Data Mining - ICDM 2011, 14 décembre 2011, Vancouver, B.C (Canada).HAL : inria-00623566.
SylvainChevallier, NicolasBredeche, HélènePaugam-Moisy & MichèleSebag (2011). « Emergence of Temporal and Spatial Synchronous Behaviors in a Foraging Swarm ». European Conference on Artificial Life, 12 août 2011, Paris (France).HAL : inria-00601780. .
LucMerchez, G.Michau, CélineRobardet, PabloJensen, PatriceAbry, PatrickFlandrin & PierreBorgnat (2011). « Peut-on attraper les utilisateurs de Vélo'v au Lasso ? ». XXIIe Colooque GRETSI. Traitement du Signal et des Images, Bordeaux (France).HAL : halshs-01314675.
LudovicArnold, SébastienRebecchi, SylvainChevallier & HélènePaugam-Moisy (2011). « An Introduction to Deep Learning ». European Symposium on Artificial Neural Networks (ESANN), 27 avril 2011, Bruges (Belgique).HAL : hal-01352061. .
KhalidBenabdeslem & MohammedHindawi (2011). « Constrained Laplacian Score for semi-supervised feature selection ». ECML/PKDD. European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases, 5 septembre 2011, Athens (Grèce), pp.204-218. doi : 10.1007/978-3-642-23780-5_23. HAL : hal-01354578.
MarcPlantevit, ChedyRaïssi & BrunoCrémilleux (2011). « Motifs séquentiels δ-libres ». Extraction et gestion des connaissances (EGC'2011), 29 janvier 2011, Brest (France).HAL : hal-00653579.
MohammedHindawi & KhalidBenabdeslem (2011). « Un score Laplacien sous contraintes pour la sélection de variables en mode semi-supervisé ». Journées Fouille de Données Complexes et de Grands Graphes, 20 juin 2011, Paris (France), pp.1-15. HAL : hal-01354584.
HDR, thèses (1)
Thèses (1)
RegisMartinez (2011). « Dynamique des systèmes cognitifs et des systèmes complexes ». HAL : hal-01461587.
CélineRobardet (2011). « Data Mining Techniques for Communities' Detection in Dynamic Social Networks ». Handbook of Research on Methods and Techniques for Studying Virtual Communities: Paradigms and Phenomena, Ben Kei Daniel, IGI Global, pp.88-102. doi : 10.4018/978-1-60960-040-2.ch005. HAL : hal-01354398.
MarcPlantevit, AnneLaurent, DominiqueLaurent, MaguelonneTeisseire & Yeow WeiChoong (2010). « Mining Multi-Dimensional and Multi-Level Sequential Patterns ». ACM Transactions on Knowledge Discovery from Data (TKDD), vol.4, n°1, pp.1-37. doi : 10.1145/1644873.1644877. HAL : lirmm-00617320. .
MatiGoldberg, MaurizioDe Pittà, VladislavVolman, HuguesBerry & EshelBen-Jacob (2010). « Nonlinear gap junctions enable long-distance propagation of pulsating calcium waves in astrocyte networks. ». PLoS Computational Biology. doi : 10.1371/journal.pcbi.1000909. HAL : inria-00575656. .
RuggeroPensa, Jean-FrançoisBoulicaut, FrancescaCordero & MauricioAtzori (2010). « Co-clustering Numerical Data under User-defined Constraints ». Statistical Analysis and Data Mining, vol.3, pp.38-55. HAL : hal-01381437.
Revues nationales avec comité de lecture (3)
YoannPitarch, AnneLaurent, MarcPlantevit & PascalPoncelet (2010). « Fenêtres sur Cube ». Revue des Sciences et Technologies de l'Information - Série ISI : Ingénierie des Systèmes d'Information, vol.15, n°1, pp.9-33. doi : 10.3166/isi.15.1.9-33. HAL : lirmm-00798834. .
PabloJensen, Jean-BaptisteRouquier, NicolasOvtracht & CélineRobardet (2010). « Characterizing the speed and paths of shared bicycles in Lyon ». Transportation Research Part D: Transport and Environment, vol.15, n°8, pp.522-524. doi : 10.1016/j.trd.2010.07.002. ArXiv : 1011.6266. HAL : hal-00541307. .
KhalidBenabdeslem, HaythamElghazel & RakiaJaziri (2010). « Un cadre graphique pour la visualisation et la caractérisation de classes en mode non-supervisé ». RNTI, pp.17-33. HAL : hal-01381631.
Conférences (16)
Conférences internationales avec comité de lecture (11)
SylvainChevallier, HélènePaugam-Moisy & MichèleSebag (2010). « SpikeAnts, a spiking neuron network modelling the emergence of organization in a complex system ». NIPS'2010, 9 décembre 2010, Vancouver (Canada), pp.379-387. HAL : inria-00545669. .
AndreeaJulea, NicolasMéger, EmmanuelTrouvé, PhilippeBolon, ChristopheRigotti, RenaudFallourd, Jean-MarieNicolas, GabrielVasile, MichelGayet al. (2010). « Spatio-Temporal Mining of PolSAR Satellite Image Time Series ». The 2010 European Space Agency Living Planet Symposium, 2 juillet 2010, Bergen (Norvège), p.6. HAL : hal-00504655.
AndreeaJulea, NicolasMéger, ChristopheRigotti, M. -P.Doin, CécileLasserre, EmmanuelTrouvé, PhilippeBolon & VasileLazarescu (2010). « Extraction of Frequent Grouped Sequential Patterns from Satellite Image Time Series ». IEEE International Geoscience and Remote Sensing Symposium, IGARSS 2010., 30 juillet 2010, Honolulu (États-Unis), p.4. HAL : hal-00520601.
AnthonyMouraud, HélènePaugam-Moisy & AlainGuillaume (2010). « The DAMNED Simulator for Implementing a Dynamic Model of the Network Controlling Saccadic Eye Movements ». ICANN'2010, International Conference on Artificial Neural Networks, 18 septembre 2010, Thessaloniki (Grèce).HAL : inria-00545670. .
LudovicArnold, HélènePaugam-Moisy & MichèleSebag (2010). « Unsupervised Layer-Wise Model Selection in Deep Neural Networks ». 19th European Conference on Artificial Intelligence (ECAI'10), 20 août 2010, Lisbon (Portugal).doi : 10.3233/978-1-60750-606-5-915. HAL : hal-00488338. .
Thi Kim NganNguyen, LoïcCerf, MarcPlantevit & Jean-FrançoisBoulicaut (2010). « Discovering Inter-Dimensional Rules in Dynamic Graphs ». Workshop on Dynamic Networks and Knowledge Discovery DyNaK'10 co-located with ECML PKDD 2010, 24 septembre 2010, Barcelona, Spain (Espagne), pp.1-12. HAL : hal-01381535.
FlorentArthaud & SergeFenet (2010). « Biodiversity modelling and optimization in pond networks ». International Workshop onConstraint Reasoning and Optimization for Computational Sustainability, 15 juin 2010, Bologne (Italie), inconnue. HAL : hal-01381478.
JérémyBesson, IevaMitasiunaite, AudroneLupeikiene & Jean-FrançoisBoulicaut (2010). « Comparing Intended and Real Usage in Web Portals: Temporal Logic and Data Mining ». 13th International Conference on Business Information Systems BIS 2010, 3 mai 2010, Berlin (Allemagne), pp.83-93. doi : 10.1007/978-3-642-12814-1_8. HAL : hal-01381453.
PeggyCellier, ThierryCharnois, MarcPlantevit & BrunoCrémilleux (2010). « Recursive Sequence Mining to Discover Named Entity Relations ». 9th International Symposium on Intelligent Data Analysis (IDA'10), 21 mai 2010, Tucson, Arizona, United States (États-Unis), pp.30-41. HAL : hal-01016928. .
PeggyCellier, ThierryCharnois & MarcPlantevit (2010). « Sequential Patterns to Discover and Characterise Biological Relations ». 11th International Conference on Intelligent Text Processing and Computational Linguistics (CICLing'10), 27 mars 2010, Iasi, Romania (Roumanie), pp.537-548. HAL : hal-01017207. .
Conférences nationales avec comité de lecture (5)
LudovicArnold, HélènePaugam-Moisy & MichèleSebag (2010). « Optimisation de la Topologie pour les Réseaux de Neurones Profonds ». 17e congrès francophone AFRIF-AFIA Reconnaissance des Formes et Intelligence Artificielle - RFIA 2010, 22 janvier 2010, Caen (France).HAL : hal-00437538. .
SylvainChevallier, HelenePaugam-Moisy & MichèleSebag (2010). « SpikeAnts : un réseau de neurones impulsionnels pour modéliser l'émergence de l'organisation ». Cinquième conférence française de Neurosciences Computationnelles, 8 octobre 2010, Lyon (France), pp.114-119. HAL : inria-00529514. .
Thi Kim NganNguyen, LoïcCerf & Jean-FrançoisBoulicaut (2010). « Sémantiques et Calculs de Règles Descriptives dans une Relation n-aire ». Actes des 26èmes journées Bases de Données Avancées BDA'10, 19 octobre 2010, Toulouse (France), pp.1-20. HAL : hal-01381534.
DominiqueGay, LoïcCerf, NazhaSelmaoui-Folcher & Jean-FrançoisBoulicaut (2010). « Un nouveau cadre de travail pour la classification associative dans les données aux classes disproportionnées ». Actes des 17ème Rencontres de la Société Francophone de Classification SFC'10, 9 juin 2010, Saint Denis de la Réunion (France), pp.47-50. HAL : hal-01381485.
SergeFenet (2010). « Lier les échelles de modèles pour l'optimisation dans les systèmes du vivant ». Congrès de la Société Française de Recherche Opérationnelle et d'Aide à la Décision, ROADEF 2010, 24 février 2010, Toulouse (France), inconnue. HAL : hal-01381456.
HDR, thèses (2)
Thèses (2)
AntoineCoulon (2010). « Stochasticité de l'expression génique et régulation transcriptionnelle -- Modélisation de la dynamique spatiale et temporelle des structures multiprotéiques ». HAL : tel-00538047. .
LoïcCerf (2010). « Constraint-Based Mining of Closed Patterns in Noisy n-ary Relations ». HAL : tel-00508534. .
HendrikBlockeel, ToonCalders, ElisaFromont, BartGoethals, AdrianaPrado & CélineRobardet (2010). « A Practical Comparative Study Of Data Mining Query Languages ». Inductive Databases and Constraint-Based Data Mining, Džeroski, Sašo; Goethals, Bart; Panov, Panče (Eds.), Springer, pp.59-78. HAL : hal-00531167. .
HendrikBlockeel, ToonCalders, ElisaFromont, BartGoethals, AdrianaPrado & CélineRobardet (2010). « Inductive Querying with Virtual Mining Views ». Inductive Databases and Constraint-Based Data Mining, Džeroski, Sašo; Goethals, Bart; Panov, Panče (Eds.), Springer, pp.265-288. HAL : hal-00531170. .
LoïcCerf, Tran Bao NhanNguyen & Jean-FrançoisBoulicaut (2010). « Mining Constrained Cross-Graph Cliques in Dynamic Networks ». Inductive Databases and Constraint-based Data Mining, Dzeroski, Goethals, Panov, Springer, pp.199-228. HAL : hal-01381541.
JérémyBesson, Jean-FrançoisBoulicaut, TiasGuns & SiegfriedNijssen (2010). « Generalizing Itemset Mining in a Constraint Programming Setting ». Inductive Databases and Constraint-Based Data Mining, S. Dzeroski, B. Goethals, and P. Panov, Springer, pp.107-126. HAL : hal-01381543.
SergeFenet (2010). « Header Based Attacks ». Encyclopedia of Cryptography and Security (2nd Ed.), Henk C.A. van Tilborg, Sushil Jajodia, Springer, pp.553-556. doi : 10.1007/978-1-4419-5906-5_652. HAL : hal-01381457.
ChristopheRigotti, IevaMitasiunaite, JérémyBesson, LaureneMeyniel, Jean-FrançoisBoulicaut & OlivierGandrillon (2010). « Using a Solver over the String Pattern Domain to Analyse Gene Promoter Sequences ». Inductive Databases and Constraint-Based Data Mining, S. Dzeroski, B. Goethals, and P. Panov, Springer, pp.407-424. HAL : hal-01381544.
Jean-FrançoisBoulicaut & BaptisteJeudy (2010). « Constraint-based Data Mining ». Data Mining and Knowledge Discovery Handbook, Maimon, Oded; Rokach, Lior, Springer, pp.339-354. HAL : hal-00567915.
Autres (2)
HélènePaugam-Moisy & RegisMartinez (2010). « Polychronous groups for analyzing self-organization in spiking neuron networks ». 1st International Workshop on "The Shapes of Brain Dynamics", 18 juin 2010, Complex System Institute, Paris (France). Poster. HAL : hal-01381579.
ThierryCharnois, MarcPlantevit, ChristopheRigotti & BrunoCrémilleux (2009). « Fouille de données séquentielles pour l'extraction d'information dans les textes ». Revue TAL : traitement automatique des langues, pp.59-87. HAL : hal-01011618. .
MarcPlantevit, ThierryCharnois, JiriKléma, ChristopheRigotti & BrunoCrémilleux (2009). « Combining Sequence and Itemset Mining to Discover Named Entities in Biomedical Texts: A New Type of Pattern ». International Journal of Data Mining, Modelling and Management, vol.1, n°2, pp.119-148. doi : 10.1504/IJDMMM.2009.026073. HAL : hal-01011378. .
EricFleury & CélineRobardet (2009). « Communities detection and the analysis of their dynamics in collaborative networks ». International Journal of Web Based Communities. doi : 10.1504/IJWBC.2009.023965. HAL : inria-00397373.
Conférences (15)
Conférences internationales avec comité de lecture (12)
RegisMartinez & HélènePaugam-Moisy (2009). « Algorithms for structural and dynamical polychronous groups detection ». ICANN'2009, International Conference on Artificial Neural Networks, 17 septembre 2009, Limassol (Chypre), pp.75-84. HAL : inria-00425514. .
ElisaFromont, AdrianaPrado & CélineRobardet (2009). « Constraint-based Subspace Clustering ». SIAM International Conference on Data Mining, 2 mai 2009, Sparks, Nevada (États-Unis), pp.26-37. HAL : hal-00362829. .
JacquesDemongeot, EricGoles & SylvainSené (2009). « Loss of Linearity and Symmetrisation in Regulatory Networks ». Advanced Information Networking and Applications Workshops, 29 mai 2009, Bradford (Royaume-Uni).doi : 10.1109/WAINA.2009.64. HAL : hal-01499511.
CélineRobardet (2009). « Constraint-based Pattern Mining in Dynamic Graphs ». IEEE International Conference on Data Mining, 6 décembre 2009, Miami, Floride (États-Unis), pp.950-955. doi : 10.1109/ICDM.2009.99. HAL : hal-01437815.
AzzedineBenameur, SergeFenet, AydaSaidane & SinhaSmriti Kumar (2009). « A Pattern-Based General Security Framework : An eBusiness Case Study ». Proc. 11th IEEE Int. Conf. on High Performance Computing and Communications HPCC'09, 25 juin 2009, Seoul (Corée du Sud), pp.339-346. doi : 10.1109/HPCC.2009.93. HAL : hal-01437680.
LoïcCerf, Tran Bao NhanNguyen & Jean-FrançoisBoulicaut (2009). « Discovering Relevant Cross-Graph Cliques in Dynamic Networks ». 18th International Symposium on Methodologies for Intelligent Systems ISMIS'09., 14 septembre 2009, Prague (République Tchèque), pp.513-522. doi : 10.1007/978-3-642-04125-9_54. HAL : hal-01437737.
BorisCule, BartGoethals & CélineRobardet (2009). « A new constraint for mining sets in sequences ». Proc. SIAM Int. Conf. on Data Mining SDM'09, 30 avril 2009, Sparks, Nevada (États-Unis), pp.317-328. doi : 10.1137/1.9781611972795.28. HAL : hal-01437649.
DominiqueGay, NazhaSelmaoui-Folcher & Jean-FrançoisBoulicaut (2009). « Application-independent feature construction from noisy samples ». Proc. 13th Pacific-Asia Conference on Knowledge Discovery and Data Mining PaKDD'09, 27 avril 2009, Bangkok (Thaïlande), pp.965-972. doi : 10.1007/978-3-642-01307-2_102. HAL : hal-01437621.
HenriPrade, AgnèsRico & MathieuSerrurier (2009). « Elicitation of Sugeno integrals : A version space learning perspective ». Proc. 18th Int. Symp. on Methodologies for Intelligent Systems, ISMIS'09, 17 septembre 2009, Prague, Czech Republic (République Tchèque), pp.392-401. doi : 10.1007/978-3-642-04125-9_42. HAL : hal-01437752.
AnthonyMouraud & DidierPuzenat (2009). « Simulation of Large Spiking Neural Networks on Distributed Architectures, The "DAMNED" Simulator ». Engineering Applications of Neural Networks: 11th International Conference, EANN 2009, 27 août 2009, London (Royaume-Uni), pp.359-370. doi : 10.1007/978-3-642-03969-0_33. HAL : hal-01437753.
JérémyBesson & CélineRobardet (2009). « A New Way to Aggregate Preferences: Application to Eurovision Song Contests ». IDA'07, - 15 septembre 2009, Ljubljana (Slovénie), pp.152-162. HAL : hal-01535505.
LoïcCerf, Pierre-NicolasMougel & Jean-FrançoisBoulicaut (2009). « Agglomerating Local Patterns Hierarchically with ALPHA ». Proc. 18th ACM International Conference on Information and Knowledge Management CIKM'09, 2 novembre 2009, Hong Kong (Chine), pp.1753-1756. doi : 10.1145/1645953.1646222. HAL : hal-01437766.
Conférences nationales avec comité de lecture (3)
PierreBorgnat, EricFleury, CélineRobardet & AntoineScherrer (2009). « Spatial analysis of dynamic movements of Vélo'v, Lyon's shared bicycle program ». ECCS'09, 25 septembre 2009, Warwick (Royaume-Uni).HAL : ensl-00408150. .
NazhaSelmaoui-Folcher, DominiqueGay & Jean-FrançoisBoulicaut (2009). « Construction de descripteurs pour classer à partir d'exemples bruités ». Actes des 9ème journées Extraction et Gestion de Connaissances EGC'09, RNTI-E-15, 30 janvier 2009, Strasbourg (France), pp.91-102. HAL : hal-01437615.
LoïcCerf, JérémyBesson & Jean-FrançoisBoulicaut (2009). « Extraction de motifs fermés dans des relations n-aires bruitées ». Actes 9ème Journées Extraction et Gestion de Connaissances EGC'09, RNTI-E-15, 27 janvier 2009, Strasbourg (France), pp.163-168. HAL : hal-01437616.
HDR, thèses (3)
Thèses (3)
YolandaSanchez-Dehesa (2009). « RÆvol : un modèle de génétique digitale pour étudier l'évolution des réseaux de régulation génétiques ». HAL : hal-01462010.
AnthonyMouraud (2009). « Approche distribuée pour la simulation événementielle de réseaux de neurones impulsionnels ». HAL : hal-01469513.
IevaMitasiunaite (2009). « Mining String Data under Similarity and Soft-Frequency Constraints ». HAL : hal-01459702.
AntoineCoulon, GuillaumeBeslon, FrançoisChatelain, AlexandraFuchs, OlivierGandrillon, MGineste, Jean-JacquesKupiec, CamilaMejia-Perez & AndrasPaldi (2009). « Mécanismes moléculaires et fonction biologique de la variabilité de l'expression génique à l'échelle de la cellule unique : une approche systémique ». Le Hasard au coeur de la cellule, Syllepse edition, pp.82-111. doi : 10.3917/edmat.kupie.2011.01.0082. HAL : hal-01499539.
ChristopheLavelle, HuguesBerry, GuillaumeBeslon, FranciscoGinelli, Jean-LouisGiavitto, ZoïKapoula, AndréLe Bivic, NadinePeyriéras, OvidiuRadulescuet al. (2008). « From Molecules to Organisms: Towards Multiscale Integrated Models of Biological Systems ». Theoretical Biology Insights, vol.1, pp.13-22. HAL : inria-00331281.
AntoineScherrer, PierreBorgnat, EricFleury, Jean-LoupGuillaume & CélineRobardet (2008). « Description and simulation of dynamic mobility networks ». Computer Networks, vol.52, n°15, pp.2842-2858. doi : 10.1016/j.comnet.2008.06.007. HAL : inria-00327254. .
YolandaSanchez-Dehesa, David P.Parsons, Jose MariaPena & GuillaumeBeslon (2008). « Modelling Evolution of Regulatory Networks in Artificial Bacteria ». Mathematical Modelling of Natural Phenomena, vol.3, pp.27-66. doi : 10.1051/mmnp:2008054. HAL : hal-01500393. .
JohanLeyritz, StéphaneSchicklin, SylvainBlachon, CélineKeime, CélineRobardet, Jean-FrançoisBoulicaut, JérémyBesson, Ruggero GPensa & OlivierGandrillon (2008). « SQUAT: A web tool to mine human, murine and avian SAGE data. ». BMC Bioinformatics, vol.9, p.378. doi : 10.1186/1471-2105-9-378. HAL : hal-00425133. .
HélènePaugam-Moisy, RegisMartinez & SamyBengio (2008). « Delay learning and polychronization for reservoir computing ». Neurocomputing, vol.71, pp.1143-1158. doi : 10.1016/j.neucom.2007.12.027. HAL : hal-01500331.
VineetChaoji, MohammadHasan, SaeedSalem, JérémyBesson & MohammedZaki (2008). « ORIGAMI : a novel and effective approach for mining representative orthogonal graph patterns ». Statitistical Analysis and Data Mining, vol.1, pp.67-84. doi : 10.1002/sam.10004. HAL : hal-01511074.
Conférences (13)
Conférences internationales avec comité de lecture (10)
Jean-FrançoisBoulicaut & JérémyBesson (2008). « Actionability and formal concepts: a data mining perspective ». 6th International Conference on Formal Concept Analysis ICFCA'08, 28 février 2008, Montréal (Canada), pp.14-31. doi : 10.1007/978-3-540-78137-0_2. HAL : hal-01500630. .
RuggeroPensa & Jean-FrançoisBoulicaut (2008). « Constrained co-clustering of gene expression data ». SIAM International Conference on Data Mining SDM'08, 26 avril 2008, Atlanta (États-Unis), pp.25-36. doi : 10.1137/1.9781611972788.3. HAL : hal-01500611. .
LoïcCerf, JérémyBesson, CélineRobardet & Jean-FrançoisBoulicaut (2008). « Data-Peeler: Constraint-based Closed Pattern Mining in n-ary Relations ». SIAM International Conference on Data Mining SDM'08, 26 avril 2008, Atlanta (États-Unis), pp.37-48. HAL : hal-01500635.
RuggeroPensa & Jean-FrançoisBoulicaut (2008). « Numerical Data Co-clustering via Sum-Squared Residue Minimization and User-defined Constraint Satisfaction (extended abstract) ». 16th Italian Symposium on Advanced Database Systems SEBD 2008, 25 juin 2008, Mondello (Italie), pp.279-286. HAL : hal-01501227.
Jean-FrançoisBoulicaut (2008). « If constraint-based data mining is the answer, what is the constraint ? ». 1st First International Workshop on Semantic Aspects in Data Mining SADM'08 co-located with IEEE ICDM 2008, 19 décembre 2008, Pisa (Italie), p.1. doi : 10.1109/ICDMW.2008.96. HAL : hal-01501363.
HendrikBlockeel, ToonCalders, ElisaFromont, BartGoethals, AdrianaPrado & CélineRobardet (2008). « An inductive database prototype based on virtual mining views ». SIGKDD international conference on Knowledge discovery and data mining, 27 août 2008, Las Vegas (États-Unis), pp.1061-1064. doi : 10.1145/1401890.1402019. HAL : hal-00372017. .
LoïcCerf, DominiqueGay, NazhaSelmaoui-Folcher & Jean-FrançoisBoulicaut (2008). « A Parameter-Free Associative Classification Method ». Data Warehousing and Knowledge Discovery, 10th International Conference, DaWaK 2008, 5 septembre 2008, Turin (Italie), pp.293-304. HAL : hal-01464500.
JérémyBesson, ChristopheRigotti, IevaMitasiunaite & Jean-FrançoisBoulicaut (2008). « Parameter Tuning for Differential Mining of String Patterns ». 2nd International Workshop on Domain Driven Data Mining DDDM'08 co-located with ICDM'08, 15 décembre 2008, Pise (Italie), pp.77-86. HAL : hal-01501294.
DavidMeunier & HélènePaugam-Moisy (2008). « Neural Networks for Computational Neuroscience ». European Symposium On Artificial Neural Networks, ESANN'2008, 25 avril 2008, Bruges (Belgique), pp.367-378. HAL : hal-01583685.
JérémyBesson, LoïcCerf, RémiThevenoux & Jean-FrançoisBoulicaut (2008). « Tackling closed pattern relevancy in n-ary relations ». Workshop Mining Multidimensional Data MMD'08 co-located with ECML PKDD 2008, 1 janvier 2008, Antwerp (Belgique), pp.2-16. HAL : hal-01501899.
Conférences nationales avec comité de lecture (3)
RegisMartinez & HélènePaugam-Moisy (2008). « Des groupes polychrones pour modéliser les traces mnésiques ». ARCo'08 - Connaissances : Genèse, Nature et Fonction, 3 décembre 2008, Lyon (France), pp.66-70. HAL : hal-01588950.
RuggeroPensa & Jean-FrançoisBoulicaut (2008). « Co-classification sous contraintes par la somme des résidus quadratiques. ». Actes 8° Journées Francophones Extraction et Gestion de Connaissances EGC'08, 1 février 2008, Sophia-Antipolis (France), pp.655-666. HAL : hal-01500595.
RegisMartinez & HelenePaugam-Moisy (2008). « Les groupes polychrones pour capturer l'aspect spatio-temporel de la mémorisation ». Deuxième conférence française de Neurosciences Computationnelles, "Neurocomp08", 8 octobre 2008, Marseille (France).HAL : hal-00331613. .
Jean-FrançoisBoulicaut, Michael R.Berthold & TamasHorwath (2008). « Discovery Science : 11th International Conference, DS 2008, Budapest, Hungary, October 13-16, 2008, Proceedings ». Springer. doi : 10.1007/978-3-540-88411-8. HAL : hal-01616067.
RuggeroPensa, CélineRobardet & Jean-FrançoisBoulicaut (2008). « Constraint-driven Co-Clustering of 0/1 Data ». Constrained Clustering: Advances in Algorithms, S. Basu et al., Chapman & Hall/CRC Press, pp.123-148. HAL : hal-01501910.
Autres (1)
LoïcCerf, JérémyBesson, CélineRobardet & Jean-FrançoisBoulicaut (2008). « Constrained-Based Closed Pattern Mining in n-ary Relations ». SML - Spring Workshop on Mining and Learning 2008, 1 mai 2008, Traben-Trarbach (Allemagne). Poster. HAL : hal-01501377.
2007 (19)
Revues (2)
Revues nationales avec comité de lecture (2)
SylvainBlachon, Ruggero GPensa, JérémyBesson, CélineRobardet, Jean-FrançoisBoulicaut & OlivierGandrillon (2007). « Clustering formal concepts to discover biologically relevant knowledge from gene expression data. ». In Silico Biology, vol.7, 4-5, pp.467-83. HAL : hal-00294025.
JérémyBesson, CélineRobardet & Jean-FrançoisBoulicaut (2007). « Un algorithme générique d'extraction de bi-ensembles sous contraintes dans des données booléennes ». Revue I3 - Information Interaction Intelligence, vol.HS 2007, pp.141-160. HAL : hal-01501481.
Conférences (10)
Conférences internationales avec comité de lecture (7)
DominiqueGay, NazhaSelmaoui-Folcher & Jean-FrançoisBoulicaut (2007). « Pattern-based Decision Tree Construction ». 2nd International Conference on Digital Information Management ICDIM'07, 31 octobre 2007, Lyon (France), pp.291-296. HAL : hal-01464501.
ManelBen Jdidia, CélineRobardet & EricFleury (2007). « Communities detection and analysis of their dynamics in collaborative networks ». Dynamic Virtual Communities: From Connectivity to Information Society, Lyon (France).HAL : inria-00398813.
EricFleury, Jean-LoupGuillaume, CélineRobardet & AntoineScherrer (2007). « Analysis of Dynamic Sensor Networks: Power Law Then What? ». Second International Conference on COMmunication Systems softWAre and middlewaRE (COMSWARE 2007), Bangalore (Inde).HAL : inria-00398809.
YolandaSanchez-Dehesa, LoïcCerf, Jose MariaPena, Jean-FrançoisBoulicaut & GuillaumeBeslon (2007). « Artificial Regulatory Networks Evolution ». Proc 1st Int Workshop on Machine Learning for Systems Biology MLSB 07, 25 septembre 2007, Evry (France), pp.47-52. HAL : hal-01502737. .
BernhardPfahringer, ClaireLeschi & PeterReutemann (2007). « Scaling Up Semi-supervised Learning : An Efficient and Effective LLGC Variant. ». 11th Pacific-Asia Conference on Data Mining (PAKDD 2007), 25 mai 2007, Nanjing (Chine), pp.236-247. doi : 10.1007/978-3-540-71701-0_25. HAL : hal-01511824.
MohammadHasan, VineetChaoji, SaeedSalem, JérémyBesson & MohammedZaki (2007). « ORIGAMI : Mining Representative Orthogonal Graph Patterns ». Seventh International Conference on Data Mining (ICDM'07), 28 octobre 2007, Omaha (États-Unis), pp.153-163. doi : 10.1109/ICDM.2007.45. HAL : hal-01512570.
HélènePaugam-Moisy, RegisMartinez & SamyBengio (2007). « A supervised learning approach based on STDP and polychronization in spiking neuron networks ». 15th European Symposium on Artificial Neural Networks, ESANN'07, 27 avril 2007, Bruges (Belgique), pp.427-432. HAL : hal-01583544.
Conférences nationales avec comité de lecture (3)
Jean-FrançoisBoulicaut (2007). « Don't be afraid of so many local patterns ». Dagstuhl-Seminar 07181 "Parallel Universes and Local Patterns", 4 mai 2007, Wadern (Allemagne).HAL : hal-01613963.
Jean-FrançoisBoulicaut (2007). « Condensed representations for frequent sets: theory and applications ». Seminar Kyushu University, 29 juin 2007, Fukuoka (Japon).HAL : hal-01614908.
HélènePaugam-Moisy (2007). « Learning and Self Organizing in Spiking Neuron Networks ». AMORPH Workshop, 29 janvier 2007, University of Sheffield (Royaume-Uni).HAL : hal-01589820.
HDR, thèses (3)
Thèses (3)
HunorAlbert-Lorincz (2007). « Contributions aux techniques de prise de décision et de valorisation financière ». HAL : hal-01456848.
DavidMeunier (2007). « Une modélisation évolutionniste du liage temporel ». HAL : tel-00198797. .
VirginieLefort (2007). « Évolution de second ordre et algorithmes évolutionnaires ». HAL : hal-01463021.
IevaMitasiunaite & Jean-FrançoisBoulicaut (2007). « Introducing softness into inductive queries on string databases ». Proceedings of the 2007 conference on Databases and Information Systems IV: Selected Papers from the Seventh International Baltic Conference DB&IS'2006, O. Vasilecas et al., IOS Press, pp.117-130. HAL : hal-01613721.
MircoNanni & ChristopheRigotti (2007). « Extracting Trees of Quantitative Serial Episodes ». Knowledge Discovery in Inductive Databases : 5th International Workshop, KDID 2006 Berlin, Germany, September 18, 2006 Revised Selected and Invited Papers, S. Dzeroski, J. Struyf, Springer, pp.170-188. doi : 10.1007/978-3-540-75549-4_11. HAL : hal-01613806.
Autres (2)
JohanLeyritz, CélineKeime, SylvainBlachon, CélineRobardet, Jean-FrançoisBoulicaut, JérémyBesson, RuggeroPensa & OlivierGandrillon (2007). « SQUAT: a web tool to mine SAGE data. ». Journées Ouvertes Biologie Informatique Mathématiques, JOBIM'07, 12 juillet 2007, Marseille (France). Poster. HAL : hal-01590433.
LoïcCerf, JérémyBesson, CélineRobardet & Jean-FrançoisBoulicaut (2007). « Extraction d'hyper-rectangles fermés sous contraintes ». Atelier Bases de Données Inductives BDI'07 organisé dans le cadre de la plate-forme AFIA 2007, Grenoble (France). Poster. HAL : hal-01590451.
2006 (19)
Revues (1)
Revues internationales avec comité de lecture (1)
Ruggero G.Pensa, CélineRobardet & Jean-FrançoisBoulicaut (2006). « Supporting bi-cluster interpretation in 0/1 data by means of local patterns ». Journal of intelligent data analysis, vol.10, n°5, pp.457-467. HAL : hal-01535517.
Conférences (15)
Conférences internationales avec comité de lecture (9)
KurtDriessens, PeterReutemann, BernhardPfahringer & ClaireLeschi (2006). « Using Weighted Nearest Neighbor to Benefit from Unlabeled Data. ». 10th Pacific-Asia Conference on Data Mining (PAKDD 2006), 9 avril 2006, Singapore (Singapour), pp.60-69. doi : 10.1007/11731139_10. HAL : hal-01512565.
Ruggero GPensa, JérémyBesson, CélineRobardet & Jean-FrançoisBoulicaut (2006). « Constraint-based mining of fault-tolerant patterns from Boolean data ». KDID@ECMLPKDD, - 25 septembre 2006, porto (Portugal).HAL : hal-01535545.
JérémyBesson, CélineRobardet & Jean-FrançoisBoulicaut (2006). « Mining a new fault-tolerant pattern type as an alternative to formal concept discovery ». ICCS, 15 juillet 2006, Aalborg (Danemark).HAL : hal-01535528.
Ruggero GPensa, CélineRobardet & Jean-FrançoisBoulicaut (2006). « Towards constrained co-clustering in ordered 0/1 data sets ». ISMIS, 14 avril 2006, Bari (Italie), pp.424-434. HAL : hal-01535515.
NazhaSelmaoui-Folcher, ClaireLeschi, DominiqueGay & Jean-FrançoisBoulicaut (2006). « Feature Construction and δ-Free Sets in 0/1 Samples ». Discovery Science, 9th International Conference, DS 2006, - 10 octobre 2006, Barcelona (Espagne), pp.363-367. HAL : hal-01464502.
MircoNanni & ChristopheRigotti (2006). « Quantitative Episode Trees ». 5th International Workshop on Knowledge Discovery in Inductive Databases KDID'06 co-located with ECML PKDD 2006, 18 septembre 2006, Berlin (Allemagne), pp.95-106. HAL : hal-01613789.
AlexandreSaidi (2006). « Using Grammatical Inference for Structure Induction in Practical Text Mining Process ». 15th International Conference on Computing (CIC'06), 24 novembre 2006, Mexico (Mexique), pp.92-104. doi : 10.1109/CIC.2006.71. HAL : hal-01614154. .
ClémentFaure, SylvieDelprat, Jean-FrançoisBoulicaut & AlainMille (2006). « Iterative bayesian network implementation by using annotated association rules ». 15th International Conference on Knowledge Engineering and Knowledge Management EKAW'06, 2 septembre 2006, Podebrady (République Tchèque), pp.326-333. doi : 10.1007/11891451_29. HAL : hal-01592340.
Conférences nationales avec comité de lecture (6)
Jean-FrançoisBoulicaut (2006). « If inductive querying is the answer, what is the question? ». Colloquium University of Konstanz, 6 décembre 2006, Konstanz (Allemagne).HAL : hal-01615330.
Jean-FrançoisBoulicaut (2006). « Inductive databases: new concepts for data-driven knowledge discovery process ». 7th International Baltic Conference on Databases and Information Systems DB&IS'06, 6 juillet 2006, Vilnius (Lituanie).HAL : hal-01613900.
HunorAlbert-Lorincz & Jean-FrançoisBoulicaut (2006). « Amélioration des indicateurs techniques pour l'analyse du marché financier ». Actes 6ème Journées Francophones Extraction et Gestion de Connaissances, EGC'06, 20 janvier 2006, Lille (France), pp.693-704. HAL : hal-01613484.
DavidMeunier, RegisMartinez & HélènePaugam-Moisy (2006). « Assemblées Temporelles dans les Réseaux de Neurones Impulsionnels ». 1ère Conférence francophone NEUROscience COMPutationnelles, NEUROCOMP 2006, 23 octobre 2006, Pont-à-Mousson (France), pp.187-190. HAL : hal-01582493.
AnthonyMouraud & HélènePaugam-Moisy (2006). « DAMNED, un simulateur parallèle et événementiel, pour rèseaux de neurones impulsionnels ». 1ère conférence française de Neurosciences COMPutationnelles, NeuroComp 2006, 23 octobre 2006, Pont-à-Mousson (France), pp.120-123. HAL : hal-01583554.
HDR, thèses (1)
Thèses (1)
Ruggero GaetanoPensa (2006). « Un Cadre générique pour la co-classification sous contraintes ». HAL : hal-01455537.
CélineRobardet, Ruggero GaetanoPensa, JérémyBesson & Jean-FrançoisBoulicaut (2006). « Contribution to gene expression data analysis by means of set pattern mining ». Constraint-based mining and Inductive Databases. HAL : hal-01535548.
Autres (1)
CorrineBresson, CélineKeime, ClaudineFaure, YannLetrillard, IevaMitasiunaite, ChristopheRigotti, Jean-FrançoisBoulicaut, AmelBendjeladi, NajateBenhraet al. (2006). « New mechanisms of v-ErbA oncogene action revealed by SAGE analysis ». Integrative Post-Genomics, IPG'06, 1 décembre 2006, Lyon (France). Poster. HAL : hal-01613844.
2005 (5)
Revues (1)
Revues internationales avec comité de lecture (1)
JérémyBesson, CélineRobardet, Jean-FrançoisBoulicaut & SophieRome (2005). « Constraint-based Formal Concept Mining and its Application to Microarray Data Analysis ». Intelligent Data Analysis, vol.9, n°1, pp.59-82. HAL : hal-01535568. .
Conférences (3)
Conférences internationales avec comité de lecture (3)
JérémyBesson, CélineRobardet & Jean-FrançoisBoulicaut (2005). « Approximation de concepts formels par des bi-ensembles denses et pertinents ». Actes de la conférence francophone d'apprentissage automatique, CAp 2005, 3 juin 2005, Nice (France), pp.313-328. HAL : hal-01535553.
CélineRobardet, Ruggero GPensa & Jean-FrançoisBoulicaut (2005). « A bi-clustering framework for categorical data ». 9th European Conf. on Principles and Practice of Knowledge Discovery in Databases, PKDD'05, 30 septembre 2005, Porto (Portugal), pp.643-650. doi : 10.1007/11564126_68. HAL : hal-01535565.
JérémyBesson, Ruggero G.Pensa, CélineRobardet & Jean-FrançoisBoulicaut (2005). « Constraint-based Mining of Fault Tolerant Patterns from Boolean Data ». KDID@ECMLPKDD, 30 septembre 2005, Berlin (Allemagne).HAL : hal-01535562.
Autres (1)
SylvainBlachon, RuggeroPensa, JérémyBesson, CélineRobardet, Jean-FrançoisBoulicaut & OlivierGandrillon (2005). « Using formal concepts for biological knowledge discovery from human SAGE data ». Journées Ouvertes Biologie Informatique Mathématiques JOBIM'05, 6 juillet 2005, Lyon, France (France). Poster. HAL : hal-01534988.
2004 (1)
Conférences (1)
Conférences internationales avec comité de lecture (1)
JérémyBesson, CélineRobardet & Jean-FrançoisBoulicaut (2004). « Constraint-based mining of formal concepts in transactional data ». 8th Pacific-Asia Conference on Knowledge Discovery and Data Mining PaKDD'04, 15 mai 2004, sydney (Australie), pp.615-624. HAL : hal-01535575.
2003 (2)
Conférences (2)
Conférences internationales avec comité de lecture (2)
SylvainBlachon, CélineRobardet, Jean-FrançoisBoulicaut & OlivierGandrillon (2003). « Extraction de régularités dans des données d'expression SAGE humaines ». Actes Journée Informatique pour l'analyse du transcriptome JPGD'03, 13 janvier 2003, lyon (France).HAL : hal-01535493.
OlivierGandrillon, Jean-FrançoisBoulicaut, CélineRobardet, SylvainBlachon, JérémyBesson & SophieRome (2003). « Recherche de groupes de gènes intéressants dans des données d'expression: apport des ensembles fréquents ». Atelier Fouille de données biopuces à EGC 2003, Lyon, 22 janvier 2003, 23 janvier 2003, lyon (France).HAL : hal-01535497.
 .
. 
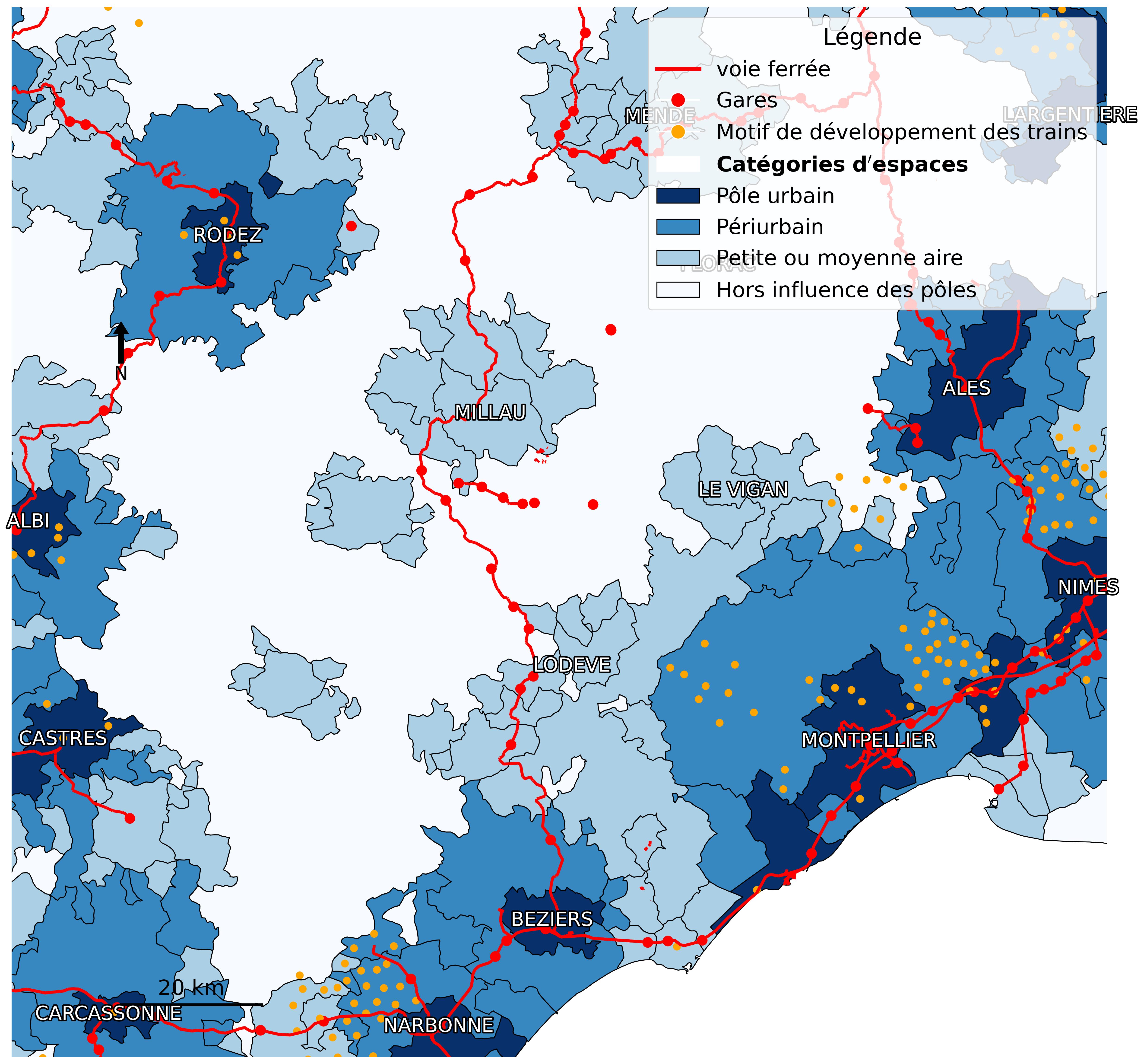 .
. 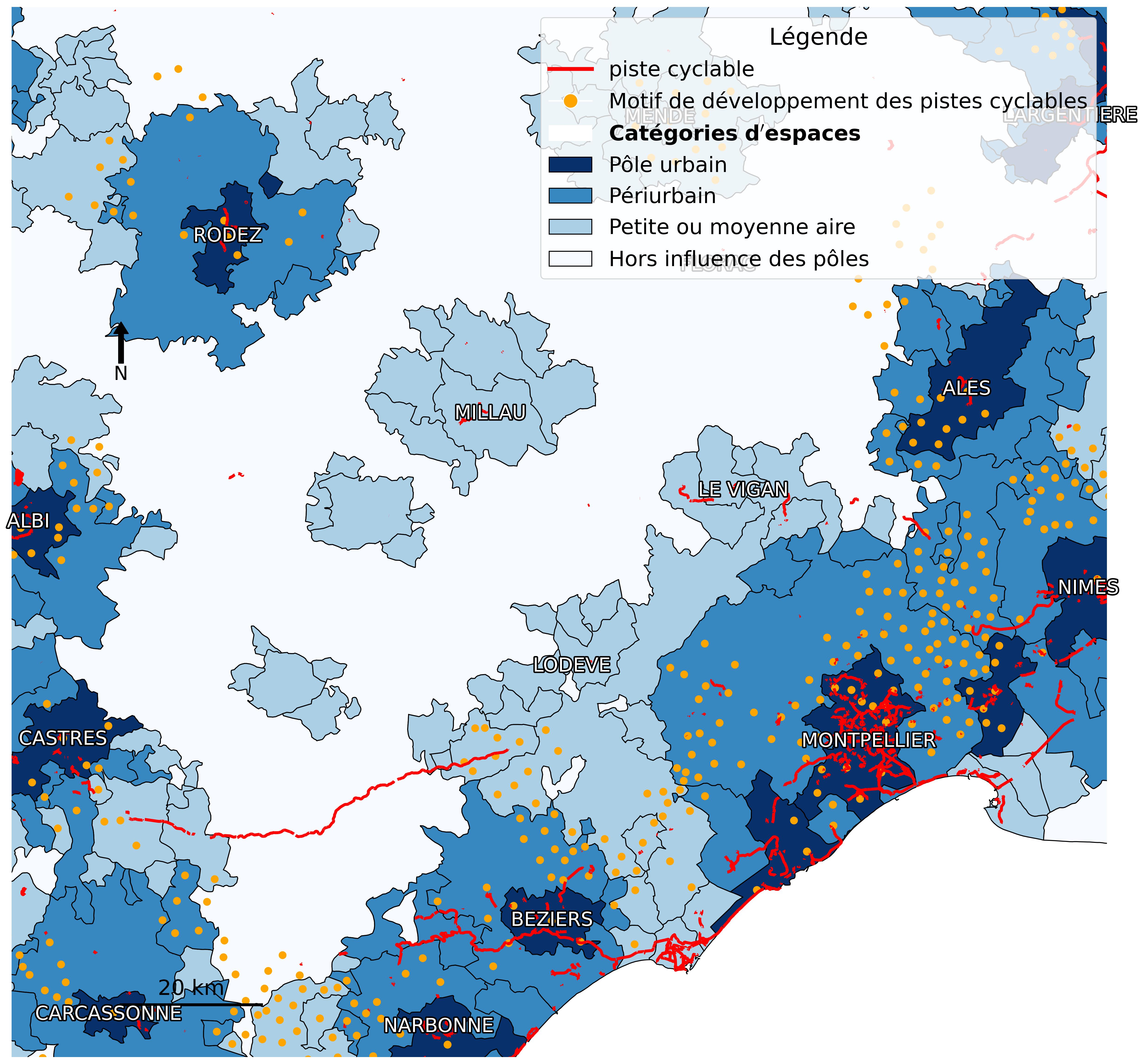 .
.  .
.  .
.