To reason effectively and quickly in a Big Data context, a lazy computation with an optimized implementation is needed. To this end, as part of the CEDAR Project, we have developed a new reasoning system we called CEDAR taxonomic reasoner. Unlike OWL reasoners whose methods of reasoning are based on variations of formula-expansion approaches (Tableaux algorithms), the CEDAR reasoner is based on an original reasoning approach which is summarized in the following items:
Using OSF as a description language formalism which is operationally lazy (i.e., it does not do anything that is not needed). Knowledge is modeled as graphs. So, we apply techniques taking advantage of that specific structure to model knowledge and perform reasoning thereon.
High classification performance: We have developed our own classification algorithm for computing the reflexive-transitive closure of a conceptual taxonomy.
Binary encoding: This technique consists in representing the elements of a taxonomy (an arbitrary poset) as bit vectors. Thus, each element has a code (a bit vector) carrying a 1 in the position corresponding to the index of any other elements that it subsumes. In this manner, the three Boolean operations (and, or and not) on sorts are readily and efficiently performed as their corresponding operations on bit-vectors. This method makes Boolean querying very efficient.
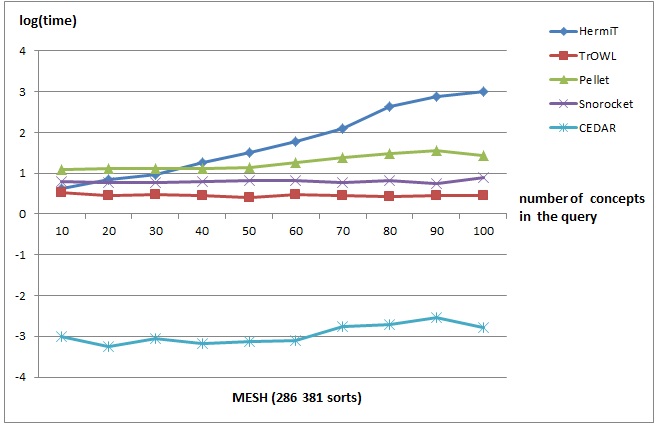
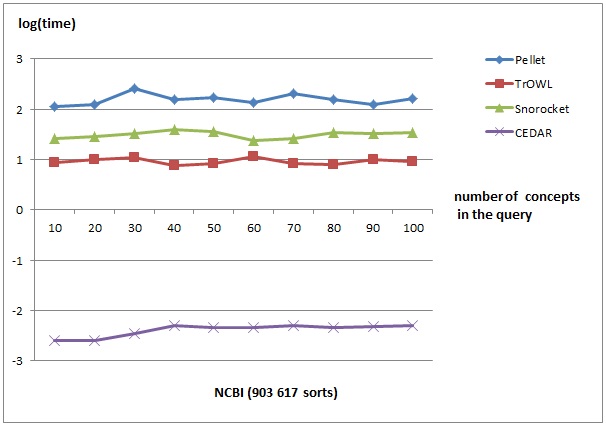
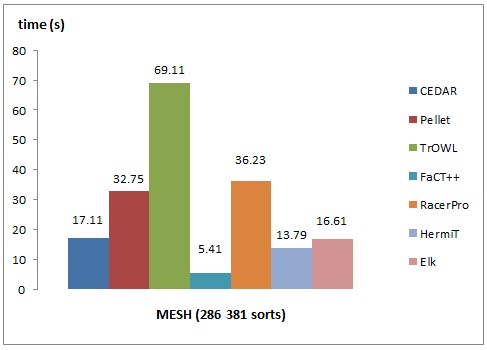
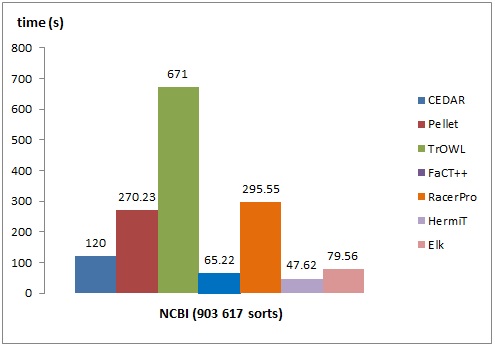
The figures below show the performance of the CEDAR taxonomic reasoner vs. several OWL reasoners. The comparison is made for classification and query answering performance. The obtained results show a comparable performance for classification and several orders-of-magnitude faster performance for query answering for the CEDAR system.